
This project is no longer active; this page is no longer updated.
Related projects: [Galley], [Parallel-I/O], [RAPID-Transit], [STARFISH]
Related keywords: [pario]
Large parallel computing systems, especially those used for scientific computation, consume and produce huge amounts of data. To provide the necessary semantics for parallel processes accessing a file, and to provide the necessary throughput for an application working with terabytes of data, requires a multiprocessor file system.
One of the big challenges facing research on parallel file systems was to develop a solid understanding of the workload: what do parallel programmers actually do with parallel file systems. In June 1993 We launched a cooperative effort, called CHARISMA (CHARacterize I/O in Scientific Multiprocessor Applications), to collect and analyze file-system traces from multiple applications on several different file systems. The CHARISMA project was unique in recording individual read and write requests in live, multiprogramming, parallel workloads (rather than from selected or non-parallel applications). The resulting papers are some of the only work to characterize production parallel computer systems.
Most parallel file systems (eg, Intel's CFS, Thinking Machines SFS) were designed around the assumption that scientific applications running on parallel computers would exhibit behavior similar to that of scientific applications running on uniprocessors and vector supercomputers.
The primary characteristics of file access in those environments are:
To test the validity of that assumption, we traced the workloads of two different parallel file systems, on two different machines, at two different sites, running primarily scientific applications. The tracing involved recording every single access that was made to the parallel file system over a period of weeks. The trace format is described in a C include file.
The two machines we traced were an Intel iPSC/860 at NASA Ames' Numerical Aerodynamic Simulation facility and a Thinking Machines CM-5 at the National Center for Supercomputing Applications. All parallel file access on the iPSC was done through Intel's Concurrent File System. Parallel applications on the CM-5 could use either the data-parallel CMF I/O library or the control parallel CMMD I/O library.
by Nils Nieuwejaar
Our observations may be summarized as follows:
We examined the millions of small, noncontiguous requests in greater detail, and found that most of them appeared to be part of regular, higher-level pattern, as follows.
We refer to a series of I/O requests as a simple-strided access pattern if each request is for the same number of bytes, and if the file pointer is incremented by the same amount between each request. Two possible situations in which this pattern could arise are shown below. The first case shows the columns of a matrix distributed across the processors in a cyclic pattern, when the number of columns is a multiple of the number of processors. The second case shows the rows of a matrix distributed across the processors. In this case, each processor reads an entire row at a time, and then skips to the beginning of the next row.
Looking at those files that were shared by multiple nodes, we found that this access pattern occurred frequently in practice. The figure below shows that many of the accesses to CFS and CMMD files appeared to be part of a simple-strided access pattern. Since consecutive access could be considered a trivial form of strided access (with an interval of 0), the figure shows the frequency of strided accesses with and without consecutive accesses included.
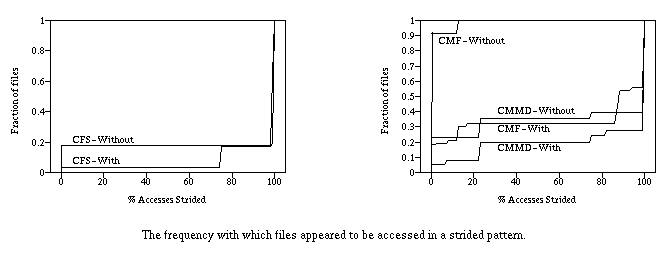
In either case, over 80% of all the mutli-node files in CFS were apparently accessed entirely with a strided pattern. Strided access was also common in CMMD, with over 60% of the files being accessed entirely in a strided, non-consecutive pattern. If we exclude consecutive access, there appeared to be almost no strided access in CMF, with no more than 20% of the requests to any file taking part in a strided pattern. This lack of strided access in CMF is not surprising, since strided access is typically caused by the explicit expression of data distribution in a control-parallel program. Accordingly, the remainder of our discussion will focus on CFS and CMMD.
We define a strided segment to be a group of requests that appear to be part of a single simple-strided pattern. While the figure above shows the percentage of requests that were involved in some strided segment, it does not tell us whether each file was accessed with a single, file-long strided segment, or with many shorter segments. The figure below shows that while most files had only a few strided segments, there were some files that were accessed with many strided segments.
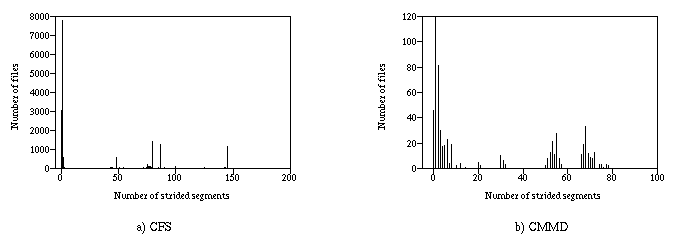
The number of requests in a segment varied between the machines. Most segments in CFS fell into the range of 20 to 30 requests and most of the segments in CMMD had 55 to 65 requests. There were some files that were accessed with much longer segments on both systems.
While the existence of these simple-strided patterns is interesting and potentially useful, the fact that many files were accessed in multiple short segments suggests that there was a level of structure beyond that described by a simple-strided pattern.
A nested-strided access pattern is similar to a simple-strided access pattern, but rather than being composed of simple requests separated by regular strides in the file, it is composed of strided segments separated by regular strides in the file. The simple-strided patterns examined above could be called singly-nested patterns. A doubly-nested pattern could correspond to the pattern generated by an application that distributed the columns of a matrix stored in row-major order across its processors in a cyclic pattern, if the columns could not be distributed evenly across the processors (below, left). Another possible source of such an access pattern is a matrix distributed in a block-cyclic pattern (below, right).
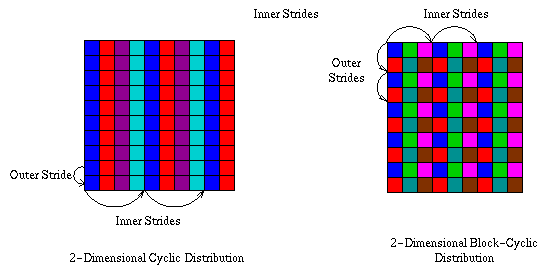
The simple-strided sub-pattern corresponds to the requests generated within each row of the matrix, while the top-level pattern corresponds to the distance between one row and the next. This access pattern could also be generated by an application that was reading a single column of data from a three-dimensional matrix. Higher levels of nesting could occur if an application mapped a multidimensional matrix onto a set of processors.
Maximum Level Number of Number of
of Nesting CFS files CMMD files
------------------------------------
0 469 38
1 10945 311
2 747 102
3 5151 148
4+ 0 3
The above table shows how frequently nested patterns occurred in CFS and CMMD. A file that had no apparent strided accesses had zero levels of nesting. Files that were accessed with only simple-strided patterns had a single level of nesting. Interestingly, on both machines it was far more common for files to exhibit three levels of nesting than two. This tendency suggests that the use of multidimensional matrices was common on both systems.
The views and conclusions contained on this site and in its documents are those of the authors and should not be interpreted as necessarily representing the official position or policies, either expressed or implied, of the sponsor(s). Any mention of specific companies or products does not imply any endorsement by the authors or by the sponsor(s).
[Also available in BibTeX]
Papers are listed in reverse-chronological order.
Follow updates with RSS.
