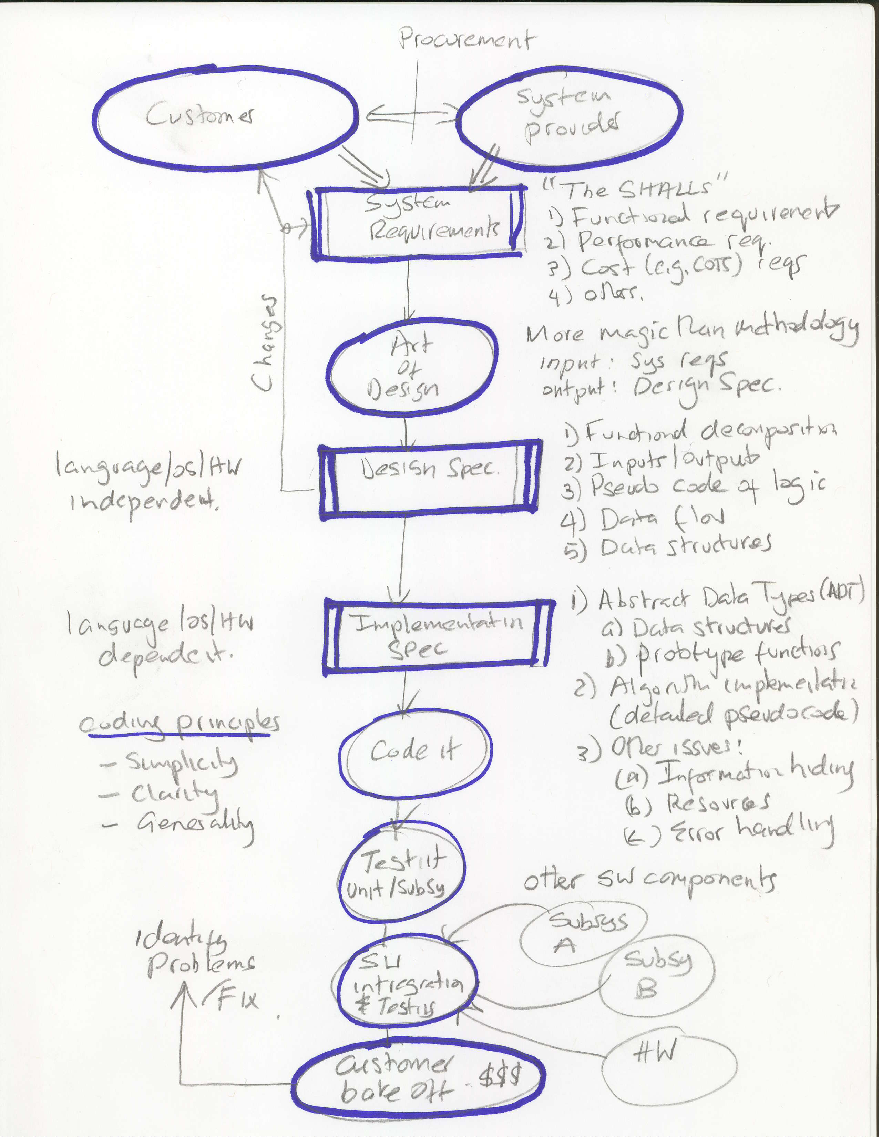
Figure 1: Software system design methodoloy
In the this lecture, we will introduce a simple software design methodology and apply it to the the top level design of the TinySearch Engine crawler.
TODO this week: We will progressively read through the paper. “Searching the Web”, Arvind Arasu, Junghoo Cho, Hector Garcia-Molina, Andreas Paepcke, Sriram Raghavan (Stanford University). ACM Transactions on Internet Technology (TOIT), Volume 1 , Issue 1 (August 2001).
Please read the these lecture notes and come armed with ideas of how you would design the crawler. Do not worry if you don’t have clear ideas but just give it some thought. For example, what data structures would you use to maintain a list of URLs that need to be searched by the crawler to maintain uniqueness? What would be the main control flow of the crawler algorithm (hint: look at its operation discussed below). Your input is welcome in class.
Methodology note. In Lab4, we will be putting functions or groups of related functions into seperate C files. We will also use the GNU make command to build our system from multiple files. We will discuss make this week and the writing of simple, clean, small functions that will be placed in their own files.
We plan to learn the following from today’s lecture:
There have been many books written on how to write good code. Some are intuitive: top-down or bottom-up design; divide and conquer (breaking the system down into smaller more understandable components), structured design (data flow-oriented design approach), object oriented design (modularity, abstraction, and information-hiding). For a quick survey of these and other techniques see“A Survey of Major Software Design Methodologies”
Many of these techniques use similar approaches. Abstraction is important, decomposition is important, having an good understanding of the translation of requirements into design of data structures and algorithms is important too. Think of how data flows through a system designed on paper is helpful. Top down is a good way to deal with complexity. But whenever I read a book or note that says something like follow these 10 steps and be assured of great system software I’m skeptical. I’m a great believer in making mistakes from building small prototype systems as a means to refine your design methodology. Clarity comes from the experience of working from requirements, through system design, implementation and testing, to integration and customer bake-off against the requirements.
We will follow a pragmatic design methodology which I used for a number of years in industry. It still includes some magic which is hard to get over. But here are a set of stepwise refinements that will lead to the development of good software.
Figure 1 shows a pragmatic software design methodology which we will use in the design of TinySearch and the projects.
The procurement phase of a project represents its early stages. It represents deep discussion between a company and provider of software systems (in our case) and a customer - yes, there has to be a customer (e.g., I’m your customer when it comes to the Labs and project) and you have to understand and capture the customers needs.
The system requirements spec captures all the requirements of the system that the customer wants built. Typically the provider and customer get into deep discussion of requirements and their cost. Sometimes these documents are written in a legal like language - for good reason. If the customer gets a system that does not meet the spec then the lawyers may get called in. If a system is late financial penalties may arise.
The system requirement spec may have a variety of requirements typically considered “the SHALLS” - the crawler SHALL crawl 1000 sites in 5 minutes (performance requirement) - these include: functional requirements, performance requirements, cost/cots requirements.
The result of starring at the system requirements for sometime and applying the art of design (the magic) with a design team is the definition of the Design Spec. This is a translation of requirements into design. Each requirements must be mapped to one of the systems design modules which represent a decomposition of the complete system into design modules that are said to be spect. The Design spec for a module includes:
The Design Spec represents a language/OS/HW independent specification. In principle it could be implemented in any language from micro-code to Java.
The Implementation Spec represents a further refinement and decomposition of the system. It is language/OS/HW dependent (in many cases the language abstracts the OS and HW out of the equation but not in this course). The implementation spec module includes:
Coding is the fun part of the software development cycle. Good coding principles are important in this phase. It is likely that you will spend about 20% of your time coding in industry as a software developer (that is if you don’t go to the Street). The rest of the time will be dealing with the other phases of the methodology, particularly, the last few: testing, integration, fixing problems with the product and all the meetings, yes, its a problem in the industry - too many meetings not enough code time.
Correctness
– Is the program correct (i.e., does it work) and error free. Important hey?
Clarity
– Is the code easy to read, well commented, use good names
– for variables and functions. In essence, is it easy to understand and use
– [K&P] Clarity makes sure that the code is easy to understand for people and machines.
Simplicity
– Is the code as simple as is possible.
– [K&P] Simplicity keeps the program short and manageable
Generality
– Can the program easily adapt to change or modification.
– [K&P] Generality means the code can work well in a broad range of situations and adapt
Probably the most important of all. Testing is critical. Both unit testing of code in isolation and at the various levels as it is put together (sub-system, system). We will unit test our code in a later lab. In Lab4 we will start by writing some bash test scripts to automatically run against our code. The goal of testing is to exercise all paths through the code. Most of the time (99%) the code will execute a small set of the branches in the module. So when conditions all line up and new branches fail it is hard to find those problems in large complex pieces of code. So code to test. And, write test scripts (tools) to quickly give confidence that even though 5% of new code has been added no new bugs emerged because our test scripts assure us of that.
The system starts to be incrementally put together and tested at higher levels. Subsystems could integrate many SW components, and new HW. The developer will run the integrated system against the original requirements to see if there is any gotchas. For example, performance requirements can only be tested once the full system comes together; for example, to increase the processing, communications load on the system as a means to see how it operates under load.
Anecdotal note. Many times systems collapse under load and revisions might be called for in the original design. Here is an example, I was once hired to improve the performance of a packets switched radio system. It was a wireless router. It was also written in Ada. The system took 1 second to forward a packet from its input radio to its output radio. I studied the code. After two weeks I made a radical proposal. There was no way to get the transfer down to 100 msec I told the team without redesign and recoding. However, I said if we remove all the tasking and rendezvous (a form of inter process communications) I could meet that requirement, possibly. That decision had impacts on generality because now the system looked like one large task. The change I made took 100 lines of Ada. I wrote a mailbox (double linked list) for messages passing as a replacement for process rendezvous. The comms time came down to 90 msec! Usually contractors get treated like work dogs in industry but for a week I was King. They also gave me a really juicy next design job. The message here is that study the code and thinking deeply is much more helpful than hacking your way out of the problem guns blasting!
This is when the customer sits down next to you with the original requirement spec and checks each requirement off or not as is the case many times. This phase may lead (if you are unlucky) to a system redesign and you (as software lead) getting fired.
In the Labs and project we will emphasis understanding the requirements of the system we want to build. Writing good design and implementation specs before coding. We will apply the coding principles of simplicity, clarity, and generality (we will put more weight on these as we move forward with assignments and the project). We will start doing simple program tests for Lab4 and emphasis this more with each assignment.
In what follows, we present the overall design for TinySearch search. The overall architecture presented in Figure 2 shows the following modular decomposition of the system:
Crawler, which asynchronously crawls the web and retrieves webpage starting with a seed URL. It parses the seed webpage extracts any embedded URLs that are tagged and retrieves those webpages, and so on. Once TinySearch has completed at least one complete crawling cycle (i.e., it has visited a target number of Web pages which is defined by a depth parameter on the crawler command line) then the crawler process is complete until it runs again and the indexing of the documents collected can begin.
An example of the command line interface for the crawler is as follows:
[atc crawler]$ crawler www.cs.dartmouth.edu ./data/ 2
Indexer, which asynchronously extracts all the keywords for each stored webpage and records the URL where each word was found. A lookup table is created that maintains the words that were found and their associated URLs. The result is a table that maps a word to all the URLs (webpages) where the word was found.
Query Engine, which asynchronously managed requests and responses from users. The query module checks the index to retrieve the pages that have references to search keywords. Because the number of hits can be high (e.g., 117,000 for fly fishing Vermont) there is a need for a ranking module to rank the results (e.g., high to low number of instances of a keyword on a page). The ranking module needs to sort the results retrieved when checking the index to provide the user with the pages they are more likely looking for.
In what follows, we will focus on the design of the crawler which will be implemented as part of Lab4. The crawler module receives a seed URL address and generates a repository of pages in the file system based on the unique URLs it finds. The remaining information in these notes refer only to the crawler design. We will discuss the Indexer and Query Engine in later lectures.
Design, implement, and test (but not exhaustively at this stage) a standalone crawler the TinySearch. The design of crawler will be done in class. In the next lecture we will develop a DESIGN SPEC for the crawler module. We will also develop an IMPLEMENTATION SPEC. Based on these two specs you will have a blueprint of the system to develop your own implementation that you can test.
The crawler is a standalone program that crawls the web and retrieves webpage starting with a seed URL. It parses the seed webpage extracts any embedded URLs that are tagged and retrieves those webpage, and so on. Once TinySearch has completed at least one complete crawling cycle (i.e., it has visited a target number of Web pages which is defined by a depth parameter on the crawler command line) then the crawler process will complete its operation.
The REQUIREMENTS of the crawler are as follows. The crawler SHALL (a term here that means requirement):
The TinySearch architecture is shown in Figure 2. Observe the crawled webpages saved with unique document ID as the file name. The URL and the current depth of the search is stored in each file.
When does it complete? The crawler cycle completes when either all the URLs in the URL list are visited or an external stop command is issued. Note, the crawler stops retrieving new webpages once its as reached the depth of the depth parameter. For example, if the depth is 0 then only the seed wepage is retrieved. If the depth is 1 then only the seed page is retrieved and the pages of the URLs embedded in the seed page. If the depth is 2 then the seed page is retrieved, all the pages pointed to by URLs in the seed page, and then all the pages pointed to by URLs in those pages. You can see the greater the depth the more webpages stoted. The depth parameter tunes the number of pages that the crawler will retrieve.
Need to sleep. Because webservers DO NOT like crawlers (think about why) they will block your crawler based on its address. THIS is a real problem. Why? Imagine your launch your spiffy TinySearch crawler and crawl the New York Times webpage continuously and fast. The New York Times server will try and serve your pages as fast as it can. Imagine 100s of crawlers launched against the server? Yes, it would spend an increasing amount of time serving crawlers and not customers - people like the lecturer.
But, wait. What would the New York Times do if it detects you crawling to heavily from a domain dartmouth.edu? It would likely block the domain, i.e., the complete dartmouth community! What would that mean? Probably, Jim Wright wouldn’t be able to read his New York Times and I’m toast. So what should we do? Well let’s try and not look like a crawler to the New York Times website. Let’s introduce a delay. Just like spy - recall? - lets sleep for a period INTERVAL_PER_FETCH between successive crawler cycles. Sneaky hey?
The crawler command takes the following input:
The output of your crawler program should be:
Once the crawler starts to run it gets wget to download the SEED_URL then its starts to process each webpage hunting for new URLs. A parser function (which we will provide to you) runs through its webpage looking for URLs. These are stored in a URLList for later processing. The crawler must remove duplicate URLs that it finds (or better it marks that it has visited a webpage (URL) and does not visit again even it it finds the same URL again. There are also conditions of stale URLs that give “Page Not Found”. It has to be able to keep on processing the URLs even if it encounters a bad link.
Below is a snipped when the program starts to crawl the CS webserver to a depth of 2. Meaning it will attempt to visit all URLs in the main CS webpage and then all URLs in those pages. The crawler prints status information as it goes along (this could be used in debug mode to observe the operation of the crawler as it moves through its workload). Note, you should use a LOGSTATUS macro that can be set when compiling to switch these status print outs on or off. In addition, you should be able to write the output to a logfile to look at later should you wish.
In the snippet, the program get the SEED_URL page then prints out all the URLs it finds and then crawls http://www.cs.dartmouth.edu/index.php next. PHP is a scripting language that produces HTML - .php provides a valid webpage just like .html In the snippet it only get two webpages.
For each URL crawled the program creates a file and places in the file the URL and filename. But for a CRAWLING_DEPTH = 2 as in this example there are a large amount of webpages are crawled and files created. For example, if we look at the files created in the [TARGET_DIRECTORY] pages directory in this case, then crawler creates 184 files (184 webpages) of 3.2 Megabtes. That means a depth of 2 on the departmental webpage there are 184 unique URLs. Note, webpages are dynamic so there may be many more than 184 unqiue URLs by the time you run your crawler.
Note, that each webpage is saved as a unique document ID starting at 1 and incrementing by one. Below we less three files (viz. 1, 5, 139). As you can see the crawler has stored the URL and the current depth value when the page was crawled.
