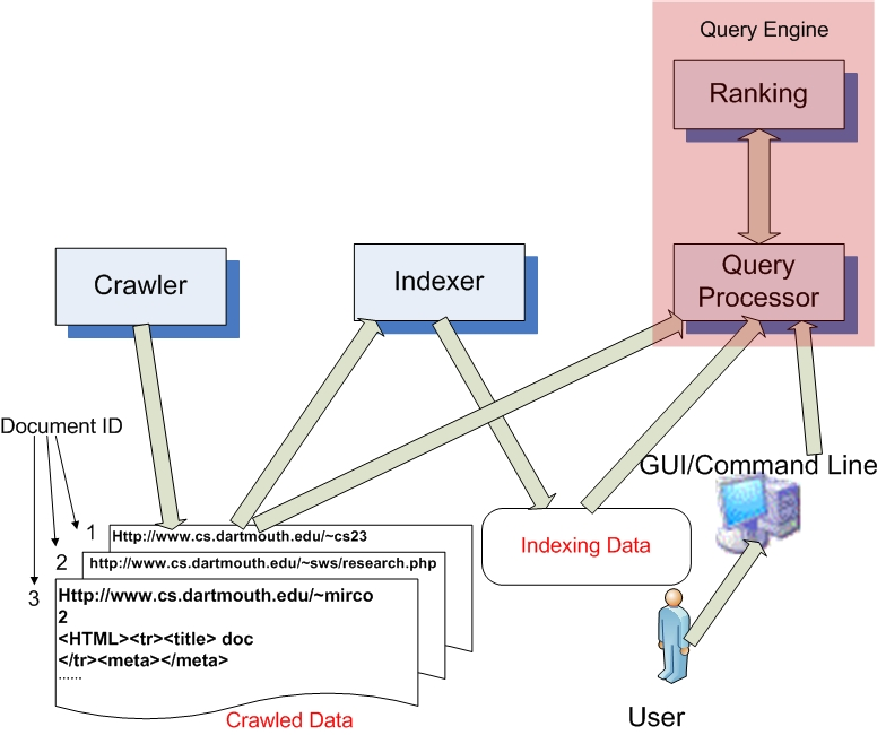
Figure 1: Indexer: reads and parses the saved files and creates an inverted index before writing
out the data to a stored file.
Lab5 is the second in a three part series of labs associated with building your very own search engine - the TinySearch Engine, specifically designed for this Dartmouth course.
We have coded the crawler and have the files in our TARGET_DIRECTORY and now we need to index them. Before you do another thing please read Section 4 on Indexing in “Searching the Web”, Arvind Arasu, Junghoo Cho, Hector Garcia-Molina, Andreas Paepcke, Sriram Raghavan (Stanford University). ACM Transactions on Internet Technology (TOIT), Volume 1 , Issue 1 (August 2001). It is important to get a good understanding of what indexing is all about. It represents a critical part of the search engines operation.
Note, you will have to come up with the Design Spec and the Implementation Spec for the Indexer in addition to coding, debugging and writing a bash shell to build, run and simply test it. We will discuss some aspects of the design below including data structures and functions but you are free to come up with your own design - which is a good excerise.
This is a another challenging assignment. It includes data structures of link lists and hash tables and functions. It certainly builds on Lab4. You will be able to reuse code - i.e.,. refactor your code.
This lab will cover many aspects of the C that you are becoming more familiar with: structures, pointers, string processing, malloc/free, file operations and management. And, debugging segfaults!
This lab is different from the crawler since it runs as a standalone program and does not interact with other distributed components such as the crawler did (e.g., wget). Each of the TinySearch components (i.e., the crawler, indexer and query engine) are designed to run independently or asynchronously.
In the case of the indexer you will need to provide functional decomposition of the problem into multiple source files. You will submit a make file to build the indexer. Also include a bash script that tests your indexer program, as was the case with the crawler.
Grading: Grading rubric for lab.
Submitting assignment using Subversion Versions System (SVN) - source code management: From now on you will use SVN to sign in your source tree.
Change to your labs directory cd ~/cs50/labs This directory contains your lab5 directory where your solutions are found.
Please make sure that the labs5 directory contains a simple text file, named README, describing anything “unusual” about how your solutions should be located, executed, and considered.
Now, submit your work to your svn directory lab6 of your own repository. You should provide the necessary files as discussed above. You need to sign in the complete source tree to svn.
We will sign it out. You should sign in the final snapshot by the deadline.
Coding style: Please put comments in your programs to help increase its understanding. Include a header in each C file including the file name; brief description of the program; inputs; and outputs. It is important you write C programs defensively; that is, you need to check the program’s input and provide appropriate warning or error messages back to the user in terms of the program usage. If you call functions from your code make sure you check the return status (if available) and print out meaningful error messages and take suitable action. See testing below.
Makefile. Your directory will include a Makefile that will be used to do a build of your system. As part of grading your lab we will do a build using your makefile. In fact your bash shell should first issue a make clean and then make indexer before testing the new indexer. There should be no warnings from the compiler nor segfaults when the code runs!
Writing a bash test script to automatically test your indexer program. You will also be asked to write a test shell that calls you indexer program. Note, we expect that the test script and the log file from the tests will be included in your tarball. Call the test script indexer_test.sh and the log of what the test prints out should be directed to a file called indexer_testlog.‘date‘ (i.e., crawler_testlog.Wed Jan 30 02:17:20 EST 2008). Again, these two files must be included in your tarball. As part of your grade we will run you script against your code and look the new log produced. Please make sure that your test script writes out the name of the test, expected results and what the systems outputs. Take a look at the test script returned as part of lab4 for a good example. Remember that the script should issue make clean and make indexer commands, as discussed above.
Test the indexer after running crawler at depth 3. Please note that the indexer should be tested after running the crawler at depth 3. This will create a large number of files (approx 700 files) that will be indexed.
We will not grade labs that segfault. You would not buy a product that crashed. So please do not submit a lab that has segfaults. We will not grade it. You will have to fix the segfaults and resubmit the lab. There will be penalties. This is in fairness to students that submited labs without segfaults.
____________________________________________________________________________
You need to refactor your crawler code so that it has a good decomposition. There are a number of file, list, hash, dictionary functions that can be reused by the indexer and the query engine. Because we do not do an overall design for the complete TinySearch up front in the course these common utilities are not apparent to you when you design and code the crawler in isolation from the complete system.
Please read the README included in the solution to lab4 that was mailed to you before starting to code the indexer.
What is refactoring?
“Code refactoring is the process of changing a computer program’s internal structure without modifying its external functional behavior or existing functionality, in order to improve internal quality attributes of the software. Reasons include to improve code readability, to simplify code structure, to change code to adhere to a given programming paradigm, to improve maintainability, to improve performance, or to improve extensibility”
Citation http://en.wikipedia.org/wiki/Code_refactoring
OK. Read the README then proceed.
Once you have completed the crawler code refactoring you can add that as another skill to your expanding sofware toolbox: i.e., refactored my code.
OK. Onward in our TinySearch quest.
The indexer sub-system uses the files created by running your crawler to generate an inverted index (called index.dat) containing the occurrences of words found in the files. The goal of the indexer is to create an index containing identifiers to webpages where a certain word (e.g., fishing) appears including the frequency of the word found in webpages. The identifiers represent the names of the files (i.e., the progressive integer numbers used to name the files saved by the crawler).
The high level requirements of the indexer are as follows. The indexer SHALL (a term here that means requirement) do the following for each file/document found in the TARGET_DIRECTORY
After all the documents have been processed, the indexer will save the information to a file. This file will be used by the query engine which will be the last in the TinySearch sequence of labs.
The indexer has to be able to recreate a the index for the query engine to use in Lab6. Therefore, the operation of the indexer is as follows:
Note, that the indexer has to create the index from the files (documents) and save it to a file (e.g., index.dat). But it also has to be able to “reload” the index data structure from the index,dat for the query engine to use. So you must write the code to “reload”. We suggest that you write a simple bash script that does the following because you need to test that a index can be written to a file and reloaded - and that it is the same index. The way to do that is to create the index and write the index.dat. Then reload the index and save it to another file new_index.dat. We will discuss the indexer_test.sh at the end of this note.
Extra Credit. Another important requirement that we will check is that there are no memory leaks. Your code should always free the structures it mallocs. We would imagine that many of the crawlers submitted had memory leakes. We will talk this week about how to detect and correct memory leaks in your code. In Lab5 we are giving extra credits for code that has no memory leaks which is good coding practice. In Lab6 there will be penalties for memory leaks!
The TinySearch Engine architecture is shown in Figure 1. Observe the crawled webpages saved with unique document ID as the file name. The indexer uses this document ID to build the inverted index and parses the file for words and counts their occurrences which it stores in the data structures discussed in the next section.
The index command takes the following input as default. Please see the section on the bash script for automatically testing your code. That section describes an extension to the default command line:
From the above the command line we see that if there are 3 arguments it is the standard indexer that is called. If there are 5 arguments (see below) it assumes we are testing the ability of indexer to reconstruct the inverted index. Read on.
To test that the indexer works we need to create the inverted index and then write it to a file (e.g., index.dat) as done in the above example command line; then, we need to recontruct the inverted index from the stored file (e.g., index.dat) and then write it back to the target directory as a new file (new_index.dat). Note, that we need to be able to read the index back from file because the query engine component of TinySearch will need to do just that to reconstruct the inverted index so it can issue queries against it. More on the query engine next week. So you will be writing a function (e.g., called readFile(char *filename)) that can read in the index from the file (index.dat) and reconstruct the data structures. As part of your test script you will need to “do a diff” between the original index written to file (index.dat) and the read/rewritten one (new_index.dat). If they are the same your code that stores the original index to file (index.dat) and the code that reconstructs the index (viz. readFile(char *filename)) works. That will give you confidence that the query engine can reconstruct the correct inverted index to operate on. This all makes good sense.
If you want your indexer to test this then the command line syntax is as follows:
./indexer [TARGET_DIRECTORY] [RESULTS FILENAME] [RESULTS FILENAME] [REWRITEN FILENAME]
Example command input:
./indexer ../../data/ index.dat index.dat new_index.dat
A key design issue is the choice of data structures for storing the index. We need a data structure capable of quickly retrieving the list of documents containing the words and their frequency.
A good design represents a list of elements (defined as WordList composed of WordNodes) where each element (WordNode) stores the information about a word and a list of the documents and the frequency of the word found in the document. The list represents another linked list (defined as DocumentList) where each element in the list (DocumentNodes) contains the document identifier and the number of occurrences inside the document.
The major data structures used by the indexer are as follows. (Note, that you are free design our own structures - these are just for guidance).
The inverted list is a WordList. In the following we assume the following mapping:
When a new word w in a document d is found then addWord() is called; the program checks if a WordNode exists in the list for the word.
If the element does not exist, a new WordNode is created (malloc) with a list composed of a single WordNode (malloc) containing the identifier of the document (d) and the number of occurrences of the word in the document.
If the element exists (i.e., a WordNode containing w exists), the program inserts a new DocumentNode containing the identifier of the document (d) and the number of occurrences of the work in the document.
The complexity of finding an element is linear. In order to speed up the retrieval of finding a word in the WordList, we use a hash table. The word itself can be used as hash key. The hash table itself is an array. Each element of the hash table contains a pointer to a linked list of WordNode (i.e., WordList). When a new word is created, a hash index is computed. The hash function returns a hash index between 0 and the maximum length of the hash table. Clearly, different words might hash to the same index value - this is called a collision which we saw happen when the URL was the key in the crawler program. A new WordNode is added to the indexer list (WordList).
Consider an example. Assume that the hash index value of the word w corresponds to the position 45 in the hash table. When the element WordNode is created, the element is added at position 45. When the word w has to be retrieved, the hash function is computed, and the list in position 45 is checked (i.e., the program checks all the words in this list in order to find the WordNode with the field w).
The number of slots/bins MAX_NUMBER_OF_SLOTS should be large to to better performance (quicker access to the data structure).
To summarize, there are three possible solutions:
A dictionary (like the one used in crawler) is useful if we have a simple linked list and we want to simply add a hash table to access it without modifying the existing code. The use of the dictionary does not require any modification to the implementation of the linked list: we are only using pointers to the elements of the existing data structure.
Start by thinking about the requirements, logic, and the design of the data structure. A good modular design of this sub-system could be based on the following set of prototype functions/pseudo code:
where:
Tip: One challenge you haev is to open each file saved in the TARGET_DIRECTORY. But how do you know how many files are stored there? Well you could do something like try and open all files with numbers 1..N until fopen fails but that would not be efficient. We recommend that you use scandir to scan the directory. scandir will return all files in a directory in a specifici scandir data structure. Checkout scandir. Make sure that you release the data structures used by scandir else you will have memory leaks. You can see the above link for help here.
If you scandir a directory there will be files for “.” and “..” which are special directory files and not regular files. You can use the stat() function and macros to help here.
This is a non ANSI library so the file that contains this scandir code should not be compiled with the - c99 flag. All the other files should use the normal mygcc compiler flags.
In the case of testing the indexer we have to save the index and the read it back from the stored file and reconstruct the data structures. In this case we need to code a function such as:
The indexer should write out the index to a file provided by the user.
Save the generated index to a text file in the following format:
Let us consider the entry cat 2 2 3 4 5: cat is the word, the number after cat is the number of documents containing the word cat; the following 2 3 means the document with identifier 2 has 3 occurrences of cat in it; the following 4 5 means that the document with identifier 4 has 5 occurrences of cat in it. moose 1 5 7 means that only one document with identifiers 5 has the word moose and moose occurs 7 times in this document.
A snippet of output could be:
Because indexer uses scandir and it’s currently not ANSI C/C99/POSIX compliant you will get make errors with the standard flags.
So assume you have a source file file.c that has a function called:
char *file;
file = FindFilesInPath(path) that uses scandir/alphasort as shown in the example in class
Then if you use the standard flags in Makefile you will get errors:
CFLAGS=-ggdb -pedantic -Wall -std=c99
you will get:
../util/file.c: In function FindFilesInPath:
../util/file.c:236:5: warning: implicit declaration of function scandir
../util/file.c:236:37: error: alphasort undeclared (first use in this function)
../util/file.c:236:37: note: each undeclared identifier is reported only once for each function it appears in
make: *** [indexer] Error 1
Because scandir in non compliant use the following flags on file.c
CFLAGS1=-ggdb -Wall
$(CC) $(CFLAGS1) -c ../util/file.c
For all other files use standard the standard flags.
CFLAGS=-ggdb -pedantic -Wall -std=c99
That’s it for make. For the final TSE programming assignment you will write a more complex Makefile that will turn all files you have refactored in /util into a library and your Makefile will link to that. But that is for next week.
Tip: regards file = FindFilesInPath(path); you can design it to return a pointer to the name of a file or NULL if no files left. The idea is that FindFilesInPath(path) would have a special case. First time it is called it calls scandir and stores all files in an internal data structure and returns a pointer to the first file. Next, time it is called it simply returns a pointer to the next file name (assuming that there are other file names). The last time it is calls there are no more names to pop off the list so it returns NULL. You can design the as you wish but this is a nice way to get one file at a time from the directory and process it (that is, index the keywords). You index logic (say buildIndexFromDirectory that returns a pointer to the inverted index) would be driven by:
INVERTED˙INDEX *buildIndexFromDirectory(char* path) {
.. code
while ((file = FindFilesInPath(path)) != NULL) {
... code
}
}
The main goal of the indexer is to keep an account of the words found in a document and its occurrence. If a word is common to a number of documents then the inverted index must keep a list of all documents that are word is found in and their occurence. The figure below shows an example inverted index. Note that the hash(“dog”) has a hash value of 47 and points to a WordNode that maintains the word (dog) and is linked into a double linked list where start and end are used to point to the start and end of the double linked list of WordNode, respectively.
Note, that three DocumentNodes are linked off the WordNode. Note, that this is an ordred single linked list (it is ordered by document ID). So three files has the word dog. Document 1 (file 1) has 1 instance and documents 2, and 5, 3 and 14 occurences, respectively. Note, that when you hash(“dog”) it returns a hash index o 47. The hash table holds pointers of WordNode.
Study this simple example.
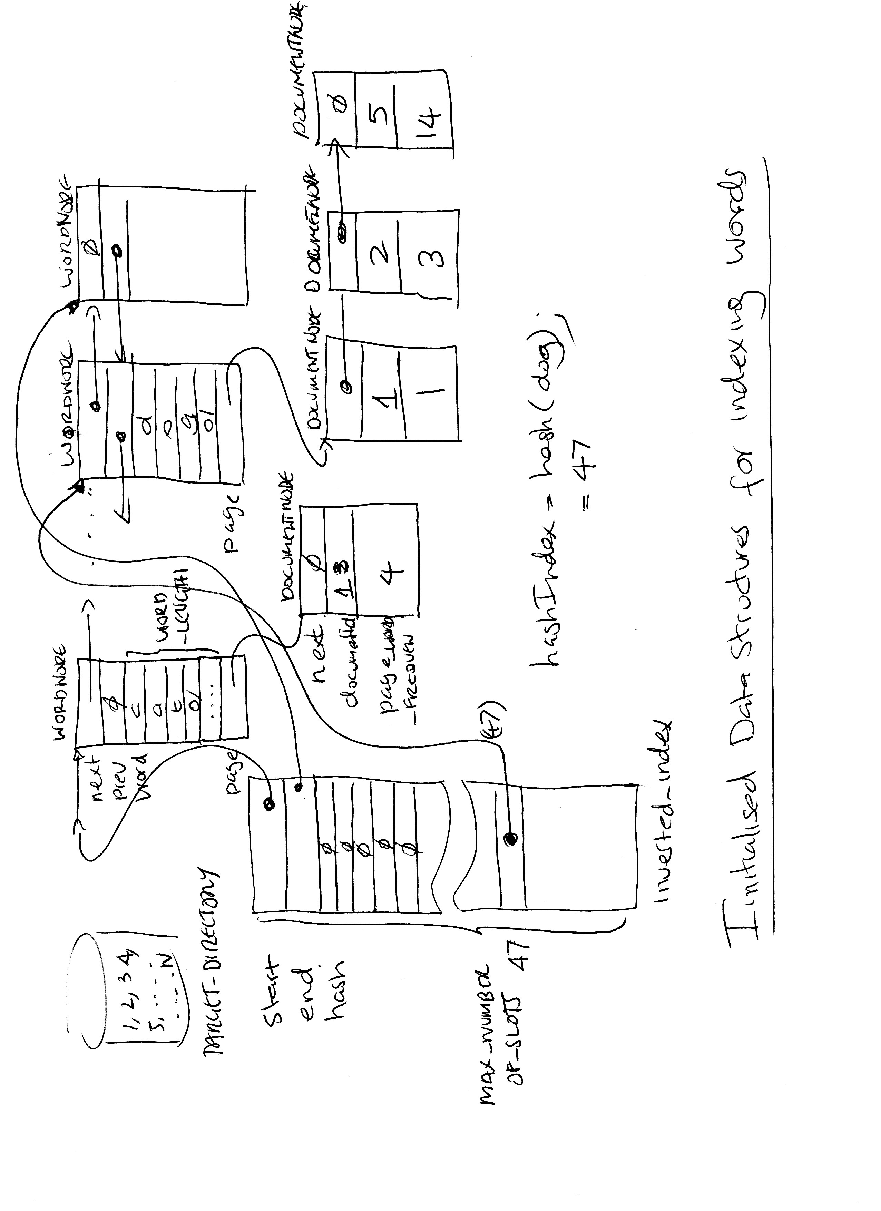
The INVERTED_INDEX is the same as the DICTIONARY used by the crawler. It provides a general double linked list and a hash table. This time the key is a word such as dog or cat rather than the URL; for example hashIndex = hash(“dog”);
Start keeps a double linked list of WordNode, which are similar to DNODES. The WordNode holds the word (dog) and point to DocumentNodes (like URLNODE in some sense). The DocumentNodes maintains the document ID (file name 1 ...N) and the word frequency (how many dogs in document 1). Because other documents may also have the word dog DocumentNodes are linked together in a single linked list for a particular word (dog). There is one WordNode per word, and the WordNode holds the start of the linked list of DocumentNodes.
The index also has to be able to “reload” the index data structure from the index.dat for the query engine to use. So you must write the code to “reload”. We suggest that you write a simple bash script that does the following because you need to test that an inverted index can be written to a file and reloaded - and that it is the same index. The way to do that is to create the index and write the index.dat. Then reload the index and save it to another file new_index.dat.
Then use the bash command diff/compare the two files. If they are the same then your code works like a dream.
You need to write the indexer_test.sh to do this.
The flow of your script will be:
#!/bin/bash
make clean
make index
DATA_PATH=../../data
INDEX_FILE=index.dat
# We index a directory, recorded it into a file (index.dat) and sort.
# Then we read index.dat to memory and write it back to see
# whether program can read in and write out index storage file correctly.
./index $DATA_PATH $INDEX_FILE $INDEX_FILE reloaded_written_new_index.dat
# you can use sort to order the keyword to look at them else they remain unordered
echo ”Index have been built, read and rewritten correctly!”
sort [parameters]
diff [parameters) # check return value of diff
echo ”Index storage passed test!”
else echo ”Index storage didn’t pass test!”
fi
#clean up any files you used
rm -f
Have a think about the structure and implementation of this bash script.
OK. You are done.
Tip: Make sure you always logout when you are done and see the prompt to login again before you leave the terminal.