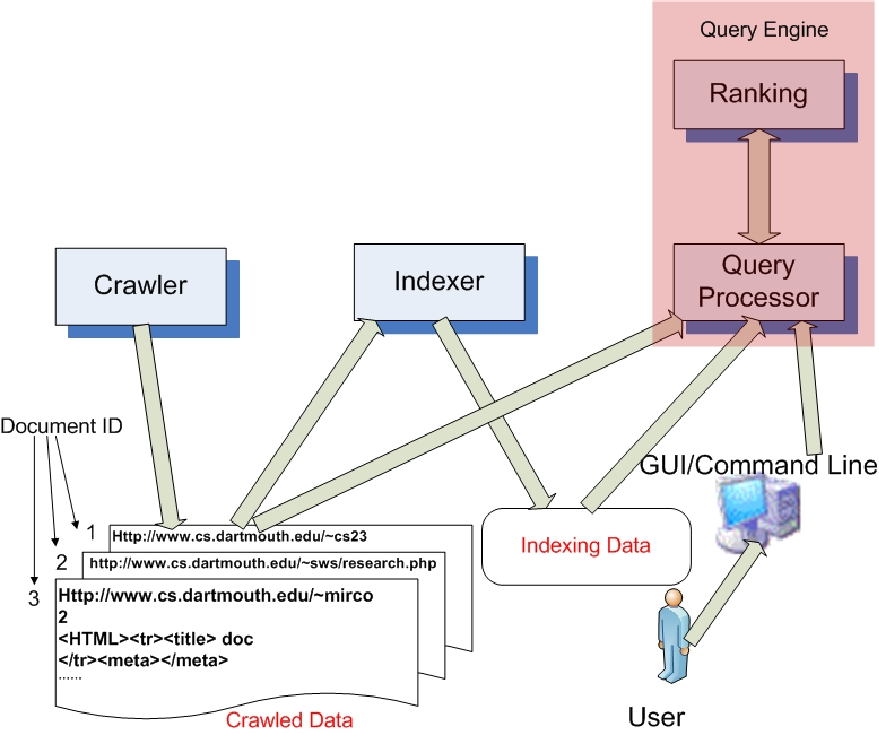
Figure 1: The TinySearch Query Engine
Lab6 is the third and final in a three part series of labs associated with building your very own search engine - the now famous TinySearch Engine!
The lab draws on all we have learnt in the course so far culmunating in putting the complete TinySearch system together.
We have coded the crawler and indexer. Now it’s time to write the front-end - and it’s not going to be a graphical user interface folks; you guessed it - we will design a simple command-line interace to the TinySearch system. This lab consists of a number of tasks that allows us to pull the system together. We will code a simple ranking system and a command-line query processor - collectively we refer to these components as the query engine. So before you do another thing please read Section 5 on Ranking and Analysis in “Searching the Web”, Arvind Arasu, Junghoo Cho, Hector Garcia-Molina, Andreas Paepcke, Sriram Raghavan (Stanford University). ACM Transactions on Internet Technology (TOIT), Volume 1 , Issue 1 (August 2001). While we will do nothing as sophisticated as this in our code it might give you some ideas for ranking should you want to implement something more creative. Feel free to do just that.
The lab also requires you to unit test your query engine code in the same manner as we discussed during the lecture on the Art of Testing: Unit Testing. You have to build a C library for the common functions found in your util sub directory. Also, there can be no memory leaks in any of your components (i.e., crawler, indexer, query engine).
Important point if you use any code provide to you as part of the solutions we have given you for the crawler or indexer then your Lab will be graded out of 80% and not 100%. The incentive here is for you to use your code and not our solution. In addition, if there are any memory leaks in your code there is an addition 10 points take off your grade.
This year 10% of the grade for this lab will be awarded to your refactoring efforts; that is, how you structured your code and developed common functions used by crawler, indexer and queryengine.
The query engine (comprising the query processor and ranking modules) is shown in Figure 1.
You will have to come up with the Design Spec and the Implementation Spec for the query engine in addition to coding, debugging, and unit testing it. Please make sure that the Design Spec and Implementation Spec details (e.g., input, output, data flow, data structures, pseudocode) are included in the appropriate places of the *.c and *.h files, respectively.
This is a another challenging assignment. In essence, the last challenging lab of the course. The final lab, i.e., Lab7, is relatively simple in comparison to this lab but the concept of sockets will be new to many of you. Sockets are the backbone programming abstraction for almost everything you do on the Internet.
Read carefully. This lab will cover a number of new issues, so read this carefully: First you need to complete the last component of the system, unit test all functions, putting the complete system together - writing a script (make_test_run_tinysearch.sh) that: 1) “makes” (Makfile) each component of the system (crawler, indexer, query engine); 2) runs your unit tests for the query engine code (and only carries on if the tests all pass) and then runs the crawler, indexer and then invokes the query engine. All stages (i.e., compilation, unit testing of query engine, running the crawler, indexer and query engine) must provably work successfully for the system to work - signing in your complete system into svn. We will checkout your TinySearch source tree and run make_test_run_tinysearch.sh. We also run valgrind against your complete system. If there are any memory leaks in your system you will have 10% deducted from your lab grade. That means you will have to go back and fix your crawler and indexer if memory leaks exist in your lab submissions. We will discuss and demo svn in the next lecture. For unit testing you can base your test harness code on the one we gave out in class. A detailed outline of the structure of the make_test_run_tinysearch.sh is given at the end of this lab note.
Submitting assignment using Subversion Versions System (SVN) - source code management: From now on you will use SVN to sign in your source tree.
In the lab6 directory creates the following sub-directories and files. Your files must be as follows:
crawler - this is the directory that holds the crawler files, README, Makefile
index - this is the directory that holds the indexer files, README, Makefile
README - this is a plain text file that describes all files and directories and how to build, test, and run the system
util - utility directory with common functions; the libtseutil.a library is built and stored here read
building my own library.At the end of those lecture notes you will find hints about building the library as
part of the Makefile in each component (crawler, indexer, queryengine)
data - data files stored here
make_test_run_tinysearch.sh - this is the bash script that makes the system (including the queryengine unit test code), tests the query engine - and if it passes all unit tests then runs the crawler, indexer and queryengine. This is a very cool script.
You should sign the complete source tree for Lab5 into your svn account before the deadline. We will sign it out and simply run the make_test_run_tinysearch.sh script. It should work. Please test this case, i.e., sign the source tree in and the change local directory and sign it all out and run the script - does it get you to the queryengine command-line? If not you have failed. If yes, we are in business. But now does the query work? That is the next thing we will test. Each student will crawl the same SEED DIRECTORY (www.cs.dartmouth.edu) to depth 3. So the number of words in the index will be the same for all student (note, CS has dynamic web pages so there might be some differences but this is not a big issue). That way the everyones TinySearch will return the same ranked URLs. So we should get the same response from inputing a query. So that is easy for us to test your system against. Then we will test combinations of queries using the logical operators. See below for some examples and an explanation of these operators.
Note, Winter 2010 I ran crawler at the following depths and this is the number of files stored in my target directory.
Depth Number of files
1 25
2 187
3 777
Make sure that you have enough file space to store the maximum number of files.
The amount of storage per student for data/ the target directory at depth 3 is:
drwxr-xr-x@ 779 atc admin 26486 Feb 10 00:50 data
The TA should check with Wayne if we are OK here.
Coding style, clarify, simplicity, generality: You know it. We will be looking for great code, great style, simple code, etc. - expect marks to be taken off if that is not the case.
Good design and implementation. You know it. Good code, nice decomposition, good unit tests, etc.
Testing at depth 3. Your submitted Tiny Search Engine must run correctly at crawler depth 3. That means the indexer will index approximately 700 files.
We will not grade labs that segfault. You would not buy a product that crashed. So please do not submit a lab that has segfaults. We will not grade it. You will have to fix the segfaults and resubmit the lab. There will be penalties. This is in fairness to students that submited labs without segfaults.
____________________________________________________________________________
The final lab in the TinySearch Engine series is demanding and includes many aspects of the course being pulled together. You have to deliver the following:
First, this assignment includes much of the indexer code, specifically, readFile(index). The query engine must build the index from a file, handle queries from the user and then search the index for matches for the key words in the query, rank them, and display the results to the user. It should continue to handle new queries until the user types control-c.
The query engine includes a query processor, and a ranking module.
The operations performed by the query engine are as follows:
The search engine should be able to process queries composed of two or more words using AND and OR as logical operators.
In other words, we assume that the queries have the following structure:
word
word1 AND word2
word1 OR word2
word1 word2 (equivalent to word1 AND word2)
In addition multiple words could be entered:
bird AND jazz or village
OR has precedence over AND. And, a space is assumed to be an AND (e.g., village vaguard).
The ranking module should use a word frequency in a HTML page to rank the results. Let’s suppose that the query is dog cat. The context score is defined as equal to the sum of the occurrences of the words in the documents taken into consideration. The search engine should assume that an AND logic operator is used. Then the query processor module consults a context index for dog and cat. For example, assume the resulting set is composed of document 1 (containing 3 dogs and 5 cats) and document 2 (containing 2 dogs and 5 cats). The score is simply derived by calculating the sum of the occurrences of both words. In this case, the score for document 1 is 8 (3+5) and the score for document 2 is 7 (2+5). Therefore, document 1 is ranked first. This is a very simple ranking scheme.
Extra Credit: There are two types of extra credits for this lab – do one of them or both if you wish. Please comments into the README to indicate if you have completed the extra credits - see below for specifics.
Testing Credit. The first is very cool because it really excercises your crawler code. I know you have that nagging feeling about your crawler – is it robust? Does it handle collisions consistently? Here is a brute force way to check. Change the size of your hash table to 10 instead of 10000 and run your crawler at depth 3. Any segfaults? In the README provide some evidence that this worked by answering the following questions: (1) Did it work without segfaults; (2) How long did it take depth 3 to run (i.e., the approximate amount of time) for hash table 10 and 10,000, respectively; (3) what were the number of files in both cases; and (4) make some summary observations looking at the gprof tool output for both cases. You have to answer (1) but try (2), (3) and (4) too for increasing credits.
Functional Credit. Feel free to implement more sophisticated ranking algorithms if you wish. Students can implement smarter techniques to improve the quality of the search results. For example, if the search word is in the title of the html document, the ranking module could assign to it a higher score. Your ideas on ranking will be rewarded an extra credit. The support of other operational words like NOT might be interesting. Finally, like google you might display an abstract or summary of where the words occurred on the html page as part of the display or ranked URLs. Take a look at google to see examples of this. Explain any extensions in the README file.
Refactoring Crawler and Indexer:
As stated in the notes above we suggest you refactor your crawler and indexer based on our design – that is, you feel that your design is not modular or functionally decomposed well enough then take a look at our design and base your refactoring on our solution for crawler and indexer. We’d like you to do this ONLY if your current design is not a good modular design that decomposes crawler and indexer into various processing units (list, file, dictionary) and their associated functions – mostly in the UTIL directory in the solution.
A student ask could he just use the functions “as is” in the solution. ANSWER: NO. You can’t just lift code for functions from the solution for example getDataWithKey() or DAdd() and use them in your refactored crawler as is. Rather, we want you to adopt a better design (if yours is poorer) and learn from changing your code to a better design and implementation.
You can do this by studying our solution and learning from it. For example, you could examine the structure of our code. You could even use the prototype definitions of some of our functions (e.g., getDataWithKey() or DAdd()), but write your own code or refactor your existing code into in body of the refactor functions. There might seem to be a thin line between reusing our code directly (not advised) and refactoring your code based on our design but there is a big difference – see penalties and honor code violations below.
Penalty:
Reuse penalty: If you submit any solution code as part of your Lab6 submission you be graded out of 80%. Warning: If you use our code to implement functions (e.g., getDataWithKey()) and the result is its our code with slightly modifies (e.g., change variable names, etc.) then the penalties apply. Note, you have to state explicitly that you reused our code if you cut and paste code in your README file. To use the code without such a citation would break our honor code.
Memory leaks penalty: If there are any memory leaks in your test programs, crawler, indexer, or query engine you get an additional 10 points taken off.
In what follows, we define the command line execution of the TinySearch and the the running program.
TinySearch allows the use to enter as many keywords and logical operators (viz. AND OR - these are reserved words) as they wish.
As part of this lab you will build your own C libray called libtseutil.a as discussed in the lecture on library
- libtseutil.a read building my own library
You will first build the library in the util/ subdirectory and then use that to build reach component. The makefiles should handle this.
You need to write a queryengine_test.c file that fully tests all you query engine functions and main code. The queryengine_test.c file should be in the queryengine/ directory.
Your queryengine_test.c should compile and link with your queryengine.c and any other files needed by make and produce a queryengine_test executable which should execute each of the test cases for each of the functions. If any test fails it should list which test failed as part of a summary. Also, the number of tests passed should be displayed.
You should follow that methodology discussed in class but because the guery engine code will be different for the dictionary.c you need to design your tests and usage cases accordingly.
Note, you do not have to unit test any code written for the indexer such as readFile(index) only new code for the query engine.
Please make sure you test as many of the different code branches in your query engine code. The more the better: the better the grade.
Following on from the last section, change local directories and sign out a clean source tree and run the make_test_run_tinysearch.sh It should cleanly compile build and test the complete tinysearch engine components.
First, run crawler_test.sh to test and run the crawler.
Next, run indexer_test.sh to test and run the indexer.
Then, build query engine – i.e., make.
Then, run the queryengine unit tests e.g., ./queryengine_test (source queryengine_test.c)
Finally, assuming the crawler and indexer were build, tested and ran correctly, launch the query engine to take user input
Note, that this make_test_run_tinysearch.sh script pulls everything together that you have done for TSE. It builds and tests each TSE component (e.g., indexer) then runs the component for the next stage to run against (i.e., query engine). This is a very cool shell script. Make sure that you code defensively and check for incorrect user input (e.g., incorrect path for the query engine).
Good luck! You are doing a great job. Almost there.