Figure 1: Keywords fly fishing Vermont - web searched in 0.19 seconds! 119,000 matches found
In the next series of lectures we will design, implement and test a simple yet powerful command-line search engine called TinySearch because it can be writtem in < 1500 lines of C (that is about 500 lines for each Lab). We will discuss the top level design of TinySearch and its decomposition into three major components; that is the crawler, indexer, and query engine modules. We will discuss the major data structures and algorithms needed to design the TinySearch.
In this lecture, we will discuss some of the foundational issues associated with searching the web. We will also dicuss the overall architectural design of a more comprehensive search engine than TinySearch.
Back before Google existed: Search engines (e.g., Google) represent our window into the web and a multiple billion dollar industry. Once you have finished the Lab4 (crawler), Lab5 (indexer), and Lab6 (query engine) you can take on Larry Page and Sergey Brin co-founders of the goliath Google. They are ready to take down and you could be David or Denise as it were. Checkout how Larry and Sergey boostrapped Google - back before Google existed.
There is one excellent technical paper from Stanford that we will ready as we move through the assignment:
Important reference: “Searching the Web”, Arvind Arasu, Junghoo Cho, Hector Garcia-Molina, Andreas Paepcke, Sriram Raghavan (Stanford University). ACM Transactions on Internet Technology (TOIT), Volume 1 , Issue 1 (August 2001).
Read this paper this week: This paper gives insights into search engine design. You can skip the plots and more research type material but do your best to get through the text on the main components and design issues of the search engine.
We will also follow some of the design, implementation and testing methodology as discussed
Other reference: “The Practice of Programming” (Addison-Wesley Professional Computing Series) by Brian W. Kernighan, Rob Pike.
We plan to learn the following from today’s lecture:
How do you get information from the Web? I’m interested in fly-fishing and Vermont. I type the keywords fly-fishing Vermont. Searching the web is something we do every day with easy but it’s technically challenging mostly because of the scale of information (i.e., webpages) on the web. So how do I get information about fly-fishing in Vermont. I query a search engine (or Google) which is an information retrieval systems and it sends me back URLs to sites that have keywords fly-fishing and Vermont embedded in them - and the URL are ranked.
Google responds to my query in 0.19 seconds with 119,000 matches found (interestingly when I did the same search two days ago I got the following response: 0.15 seconds! 117,000 - what could have changed, thoughts?). It gives me a set of ranked pages. Such a simple interactions raised a number of questions. First, the web is huge so how does Google search an estimated 15 to 30 billion web pages in 150 msecs. Surely, Google can’t do that in such a short period. The answer is that it doesn’t. But it collects a snap shot of some percentage of the estimated set of webpages cached those on at server farms and it computes and indexes those webpages against the keywords it finds in those pages such as fishing, fly, Vermont.
How does Google rank the pages it gives in response to a query? It uses a page rank scheme (which has probably evolved since its initial publication). Because webpages are updated continuously when does Google take the next snap shot of the web? That depends on multiple things. Maybe the webpages for the New York Times are “crawled” more frequently that cs50 webpages? Yes, of course they are. They are more popular and that policy feeds into when and how often Google will crawl a website. But how much storage does it take Google to crawl the web. It is estimated that Google’s search crawler uses 850 TB of information (1 TB = 1024 GB)of information (1 TB = 1024 GB). These figures are from 2009 and probably very out of date already, as the web expands.
HTML. From the description of the problem above we note a few things. First, search engines need to collect pages from the web (this is called crawling the web) and store them on servers. Webpages are typically written using the HyperText Markup Language (HTML). For a quick tutorial on HTML check out this Introduction to HTML
The basics are that HTML file is a text file containing markup tags that tell your web browser how to display the page. An HTML file must have an htm or html file extension. HTML pages can be created by tools or simply from the command line editor. Note, you will not need to write any HTML for this project but you will need to understand a little about what a HTML webpage looks like. We are interested in extracting URL from HTML webpages and words. So it you now go to you web browser while looking at this page and view course (I use Safari so it depends on your browser where the “view source” pop down is - take a look around you will find it).
Here is a snippet of the HTML of this page; that is,
http://www.cs.dartmouth.edu/~campbell/cs50/tinysearch.html
Try and look at the HTML source in one tab (window) and the rendered webpage in another.
You start to pick up the similarities.
Tags, URLs and keywords. HTML uses tags to mark-up HTML elements. There are a number of different tags in use in HTML some more common that others. In the HTML snippet above there are a number of tags; for example,
<html >, <head>, <title></title>, </head><body, <h1 class="likepartHead"}
The tutorial goes into tags in details.
We are interested collecting URLs from HTML files because we need to go and collect those pages. The URL tag important to us; that is,
<a href="http://www.google.com/corporate/history.html" >
The <a> tag defines an anchor. An anchor is used to create a link to another document by using the href or to create a bookmark inside a document using the name or id attribute. We will only consider href URLs. Tags usually come in pairs like <a> and </a> The first tag in a pair is the start tag and the second tag is the end tag and the text the tags represents the element content.
When looking at a HTML file we are interested in the keywords only. So we want to parse the HTML file for words; for example, keywords such as,
fly fishing Vermont.
Can you find these keywords in the snippet above (they are near the end). Notice that keywords are not embedded in tags. In fact, for TinySearch, we define keywords as being outside of tags.
So when TinySearch downloads a webpage of HTML source in needs to parse the page and remove URLs (because it needs to go crawl them too) and KEYWORDS that users might be interested in running queries against (such as fly fishing Vermont).
Don’t worry that you don’t know all the HTML syntax. We plan to provide you with a parser C function. Feel free not to use our parser and write your own if you like (and if you have time). If you are interested more information of the curremnt specification check out the HTML 4 specification
HTTP.HyperText Transfer Protocol (HTTP)is used between your client browser and the server to transfer plain text HTML files. The URL defines what webpage is transfered, e.g, http://www.google.com/corporate/history.html HTTP itself is a very simple request/response protocol that get its reliable transport support from TCP (the famous Transmission Control Protocol).
Want to talk to a real-life webserver? They have to be publicly open for business so we can talk plain text HTTP to them. And, if we are nice and get all the syntax right they will provide us with whatever we ask for. The basic protocol is that the client sends a request called a GET and the server responds with a response. Webservers “listen” for requests on the well-know port 80. We will talk more about IP address and ports when we cover socket programming later in the course. But suffice to say that the Computer Science webserver is listening for requests (e.g., http GET commands) at IP address 129.170.213.101 (use host www.cs.dartmouth.edu) port 80. So let’s start a conversation with the server. We have to first connect to the server and open up a reliable stream to host www.cs.dartmouth.edu at port 80 . We will use telnet to do this. After that we will form a GET message and let the server know our hostname. Then see what it will do.
Make sure you hit carriage return twice after typing in host: moose.cs.dartmouth.edu
newline
The nice webserver responds with the webpage http://www.cs.dartmouth.edu/ campbell/index.html
newline
From the snippet of HTML above you can clearly parse other URL embedded in the webpage http://www.cs.dartmouth.edu/ campbell/index.html The following URLs are embedded:
href="http://www.cs.dartmouth.edu/"
href="http://sensorlab.cs.dartmouth.edu"
href="http://www.ists.dartmouth.edu"
href="http://metrosense.cs.dartmouth.edu/"
href="http://metrosense.cs.dartmouth.edu/"
So this little snippet of HTML tells us that duplicate links exist. If wanted to imagine that the snippet represented the complete HTML for the webpage then we could parse that there are 5 embedded URLs in http://www.cs.dartmouth.edu/ campbell/index.html and that one of them is a duplicate. TinySearch will have to be able to detect and ignore duplicates. More on this when we discuss the design of the crawler. We will use hash function and hash table to make sure we only crawler unique webpages and we will not have to implement a sort function to do this. This is really cool.
When we design the crawler it will rely on wget to relieve webpages. We have already written a bash shell script that uses wget in Lab2. We will call wget using the “system()” sys call that we used in Lab3. Recall that you pas wget a URL.
Try using wget to download my hompage and store it in a file 1.html (like the crawler does) and then count the number of URLs on my homepage. There are quite a lot of embedded URLs in my homepage.
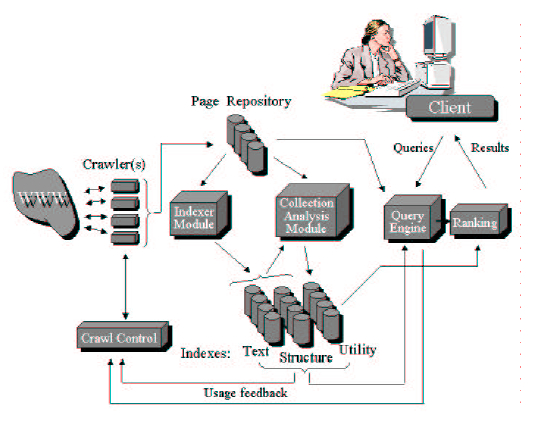
Search engines such as Google are complex, sophisticated, distributed systems. Below we reproduce the general search engine architecture discussed in “Searching the Web”, Arvind Arasu, Junghoo Cho, Hector Garcia-Molina, Andreas Paepcke, Sriram Raghavan (Stanford University). ACM Transactions on Internet Technology (TOIT), Volume 1, Issue 1 (August 2001).
The main components include, parallel crawlers/ and crawler control (when and where to crawl), page repository, indexer, analysis, collection of data structures (index tables, structure, utility), and query engine and ranking module. Such a general architecture would take a significant amount of time to code. In this course, we implement stripped down versions of the main components - we call this TinySearch - shown in Figure 2.