Intro to Relational Models
admin
Some handy links:
Relax Relational Algebra calculator, Relax models , and Relax queries.
Quick review of the relational table
A relational database model enables logical representation of the data and its relationships.
SLIDE 03-01.
- A table is perceived as a 2-dimensional structure composed of rows and columns.
- Each table row (tuple) represents a single entity occurrence within the entity set.
- Each table column represents an attribute, and each column has a distinct name and datatype.
- Each intersection of a row and column represents a single data value.
- All values in a column must conform to the same data format (datatype).
- Each column has a specific range of values known as the attribute domain.
- The order of the rows and columns is immaterial to the DBMS.
- Each table must have an attribute or combination of attributes that uniquely identifies each row (the primary key).
WHat would the primary key be for a class roster? NetId Do cars have primary keys? VIN nummbers Do people have primary keys?
Keys
Keys ensure that there is precisely one way to identify a row in a table.
More formally, “Keys are one or more attributes that determine the other attributes in a row.”
"Two tuples in R cannot agree on all of the attributes in set S, unless one of them is NULL. Any attempt to insert or update a tuple that violates this rule will cause the DBMS to reject the action that caused the violation." -- DSCB
Keys are also used to establish relationships among tables and to ensure data integrity.
The Primary Key is one or more attributes that uniquely identifies any given
row (or tuple) AND the attribute(s) making up that Primary Key cannot be
NULL.
Functional Dependence and stuff
The idea of “determination” is an important one in DB’s. We use it to “normalize” relations, thereby avoiding anomalies.
Functional dependence: Value of one or more attributes determines the value of one or more other attributes
- Determinant: Attribute whose value determines another
- Dependent: Attribute whose value is determined by the other attribute
Formally
Let be a relation schema, and and are sets of attributes. The functional dependency with as the determinant and as the dependent is written as
This functional dependency is said to hold on relation scheme if and only if for any legal relations , whenever any two tuples and of agree on the attributes , they also agree on the attributes . That is,
DRAW ON BOARD
For example: Here’s a relation :
| 4 | 1 |
| 5 | 1 |
| 7 | 3 |
Here, does hold, but does NOT hold
since
when , then , but
DRAW ON BOARD Here’s another example
Student (SSN, sName, address, Hscode, Hsname, Hscity, GPA, priority )
SSNsNameandSSNaddress(assuming a student doesn’t move during enrollment)HScodeHSname,HScityandHSname,HScityHScode(Assume no two HS with same name in one city)SSNGPA,GPApriority, thereforeSSNpriority(an example of our old friend Transitivity!)
That’s enough about functional dependence for now. We’ll return to the topic later when we learn about Normalization.
Back to keys
Now we can talk about keys more specifically.
- Composite key: a key that is composed of more than one attribute
- Key attribute: Attribute that is a part of a key
- Entity integrity: Condition in which each row in the table has its own unique
identity
- All of the values in the primary key must be unique
- No key attribute in the primary key can contain a null
Other special terms:
- A
NULLvalue implies the absence of any data value. They often represent:- A missing or unknown attribute value
- A inapplicable attribute value
- Referential integrity: Every reference to one entity instance by another entity instance is valid
Ask Students how do you identify a key?
There are a variety of keys we’ll talk about: SLIDE 03-02
There can be LOTS of candidate keys.
Let’s look at a simple DB SLIDE 03-03 OR MySQLWorkBench
OK, let’s see what kinds of keys are in this table SLIDE 03-04
-
First find the functional dependencies
- STU_NUM STU_LNAME
-
(STU_FNAME, STU_LNAME, STU_INIT, STU_PHONE) (STU_DOB, STU_HRS, STU_GPA)
- Sometimes the dependency is overspecified. Suppose we’re given:
- STU_NUM STU_GPA and
- (STU_NUM, STU_LNAME) STU_GPA Here STU_LNAME is unnecessary since we already know the dependency above.
-
Superkey - one or more attrs together that uniquely identify a row … ask students
- STU_NUM
- (STU_FNAME, STU_LNAME, STU_INIT, STU_PHONE)
-
Candidate Key - minimal Superkey
- STU_NUM
-
Foreign Key - links to other tables … ask students
- Can you think of other tables to which this one might be related?
- Draw on board
- DEPT_CODE key to DEPARTMENT table
- PROF_NUM key to FACULTY table
- ???
Note that keys must be chosen with care - what could go wrong? … ask students
- Might be NULL when data is missing
- A customer does not have a salesperson assigned to them yet
- Might not uniquely identify rows because of entities or data you didn’t expect
- E.g., once WW employees, ex-employees, and retirees exceeded 999,999 Employee number had to include country-code to ensure uniqueness
- What sort of impact would that have to the company’s databases?
Entity & Referential Integrity
For all this to work, one Candidate Key has to be selected for each table as its Primary Key.
The attribute(s) making up this key can never be NULL .
When might a NULL occur?
- no middle initial
- ASK STUDENTS FOR OTHERS
ASK STUDENTS why are NULLs problematic in a primary key?
- If it can’t uniquely identify a row/tuple
- How can you compare a
NULLto other things?
- How can you compare a
SLIDE 03-05 NULL means “no value”. Not ZERO, and not the empty string
“‘\0”
The result of any arithmetic operation involving NULL is NULL
Aggregate functions simply ignore NULL
For matching, NULL is treated like any other value, and two NULLs will
match.
-
Entity Integrity
- All primary key entries are unique and no part may be
NULL - This ensures each row will have a unique identity and that other tables can properly reference rows via the primary keys.
- Example: “No invoice can have a duplicate number or be
NULL“
- All primary key entries are unique and no part may be
-
Referential Integrity
- The entry for a Foreign Key may either be
NULLor an entry that matches a primary key in a table to which this one is related. - It’s ok to have a missing reference (e.g., no entry), but it is not ok
to have an invalid entry.
- ASK STUDENTS Think about this:
- DRAW ON BOARD
- If you have two tables linked via a Foreign Key, and you force all Foreign Keys to be non-NULL and valid, THEN it would not be possible to ever delete a row in the table to which the Foreign key refers!
- ASK STUDENTS Think about this:
- It is impossible to have an invalid invoice number on a Receipt.
- The entry for a Foreign Key may either be
SLIDE 03-06 Example of integrity rules
There are lots of ways to handle NULL, typically using values that are unique
or invalid to your app. Most DB’s allow you to specify a column as NOT NULL to
have the DB itself detect and report mistakes (either your own or your users’).
END OF DAY ONE
RELATIONAL ALGEBRA
Why do we study RA?
RA provides the formal mathematical basis for Relational DB’s.
RA is platform-independent and concise… MUCH simplier than SQL, yet complete.
Understanding RA enables the student to understand how RDBMS’s take a high-level query
in SQL and implement it as an optimised series of sub-queries.
Studying relational algebra will teach you to break down your query into smaller steps, each of them well-understood, and then compose them into a whole that produces the final result. This helps a lot of students as a methodology to get their head around the more complex queries and understand why certain solutions do or do not produce a correct answer.
SQL is declarative, describing what the user wants. Relational Algebra is procedural, describing the steps in how best to accomplish what the user wants.
Relational Algebra also has the property of closure :
- Using Relational Algebra operators on existing relations produces new relations.
Finally, Relational Algebra is based on sets, whereas SQL is based on multisets
- This means that if an RA expression would result in duplicate rows/columns, only one will be returned.
- In SQL, if a result has duplicates they will ALL be returned (unless you override this default behavior).
Relational Set Operators
SLIDE 03-07 Codd’s eight original operators: Set operators: UNION, INTERSECTION, DIFFERENCE Relation operators: JOIN, PROJECTION, SELECTION, CARTESIAN PRODUCT and DIVISION.
We’ll use these relations for examples.
NOTE: the. Github gist identifier for our ReLaX DB is:
ed68cb8c5b5436362a7b5eed9a55aba4. Here’s how to load it:
- Start ReLaX
- Click
Select DB - Paste our Github gist identifier into the input box under
Load dataset stored in a gist - Click
Load - You should now see a list of database relations on the left side of ReLaX,
beginning with
College.
The simplest operator is simply the name of the table itself. This is a valid relational algebra expression that returns the entire table.
Relational Algebra operates on relations and always produces a relation.
NOTE: The ReLaX calculator will only accept one query expression at a time. Either enter it directly or cut and paste into the input area. The exception is that one or more assignments may be entered before the actual query.
SLIDE 03-08
SELECT identifies rows, and PROJECT identifies columns.
Said another way, PROJECT eliminates columns while SELECT eliminates rows.
Go through each operator, discuss, and write examples on board
Slides through 30
**DISCUSSION**
Cross Product, or Cartesian Product
The resulting schema is the union, and the contents are all the combinations: A tuples X B tuples = # tuples in CP
If there are identical attributes, convention is to prefix them with the table name
Question: Is it ever useful to compose two projection operators?
Example:
Question: Is it ever useful to compose two selection operators?
Example:
Note Intersection doesn’t add any new expressive power to Relational Algebra
since E1 INTERSECT E2 == E1 – (E1 – E2). Explain with a Venn diagram.
Alternate representations of Relational Algebra expressions
Some of these expressions can get rather messy. There are a couple of schemes you can use to make them clearer.
Expression trees are visual aids for people, not so useful for computers.
SLIDE 03-31
Linear notation allows you to break up complex expressions using temporary variables
SLIDE 03-32
JOINS
Joins are extremely important to the relational model, as they are the means for combining tables in a variety of ways and subject to a variety of selection mechanisms.
Essentially, Joins allow information to be intelligently combined from two or more tables.
Joins are represented by the “bowtie” symbol with some variations for other JOIN operations.
There are quite a few of them, best explained visually using the superb diagram from C.K. Moffett. You might keep a copy handy.
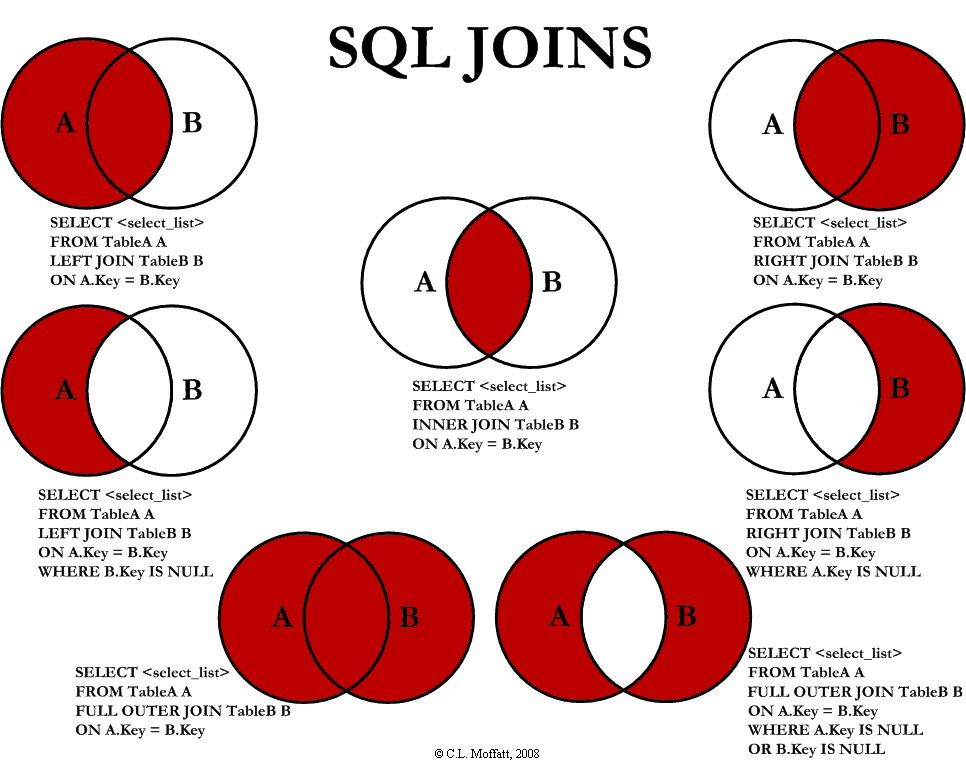{kind=link}
SLIDE 03-33
Natural join
-
Links tables by selecting all combinations of tuples in the two relations that have equal values for the two relations’ attributes with the same name.
- a.k.a. common join.
- Enforces equality on all attributes with the same name.
- Eliminates all but one copy of duplicate named attributes
-
Example (on board)
Majors
NetID Major Year 11111 COMPSCI 23 22222 COMPSCI 24 33333 BIOLOGY 23 44444 CHEMISTRY 22
MinorsNetID Minor 11111 ECONOMICS 33333 CHEMISTRY 44444 MATH
If we do an Natural Join using: we will getNetID Major Year Minor 11111 COMPSCI 23 ECONOMICS 33333 BIOLOGY 23 CHEMISTRY 44444 CHEMISTRY 22 MATH
Equijoin is a special case of natural join
- Links tables on the basis of a specified equality condition that compares specified differently-named columns from each table.
-
Example: (write on board)
EmployeesEmployee Project Smith A Black A Black B
ProjectsSecLevel Type A Classified B Unclassified A Natural Join of these tables would result in no entries as there are no attributes common to both.
Instead we do an Equijoin using:
Employee Project SecLevel Type Smith A A Classified Black A A Classified Black B B Unclassified
Inner join (most common in SQL)
Returns the rows from boith tables where their related columns match. The difference is that all the attributes from both tables and including the common column is returned.
If we use the SQL command:
SELECT * FROM Majors INNER JOIN Minors ON Majors.NetID=Minors.Netid
Results in
| NetID | Major | Year | NetID | Minor |
|---|---|---|---|---|
| 11111 | COMPSCI | 23 | 11111 | ECONOMICS |
| 33333 | BIOLOGY | 23 | 33333 | CHEMISTRY |
| 44444 | CHEMISTRY | 22 | 44444 | MATH |
Outer join
Returns the same as Inner, but also includes the rows that don’t have a matching value in the second table.
- Left outer join: Yields all of the rows in the first table, including those that do not have a matching value in the second table
- Right outer join: Yields all of the rows in the second table, including those that do not have matching values in the first table
SLIDE 03-36
Theta join
An extension of natural join, denoted by adding a subscript after the symbol. Think of it as “do a cross product then the selection using .”
Explain these, then go through several of them with examples.
**I USE SLIDES 03-30 THROUGH 03-36 TO EXPLAIN**
Self Joins
- Sometimes you need to refer to more than one row (tuple) of the same table (relation) in the same query. Similar to what we did when explaining the rename operator.
- Example:
- “Who scored more points than the player with jersey number 10 for any of the regular season games?”
- To answer this query, we need to compare two tuples p and q of the relation PlayerStats:
- tuple p, corresponding to the player with jersey number 10, and
- tuple q, corresponding to the same game as the tuple t, in which .
Aggregate Functions
SLIDE 03-37 through 03-38 some of the functions are avg, sum, min,
max, count
Algebraic Notes
- JOIN is commutative:
- JOIN’s are associative (assuming common attributes):
- Technically, “JOIN” chains need no parentheses … :
but it’s always better to have clarity rather than showing off.
-
LEFT OUTER JOIN and RIGHT OUTER JOIN are not commutative:
R ⟕ S ≠ S ⟕ R
R ⟖ S ≠ S ⟖ R -
Selection Push-Down
- If some predicate refers to attributes in only, then an optimization may be used: