DB Performance and Tuning
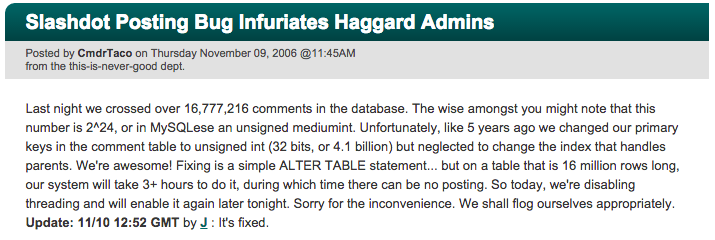
sakila examples
Let’s take a deeper look at query processing and optimization Show some example queries on sakila and compare their execution times mysql sakila usage overview , sakila sql example queries
Basic database performance-tuning concepts
– the goal of database performance improvement is to execute as many queries as fast as possible
- the activities we’ll talk about today all aim to reduce database response time.
- There are a lot of moving parts that must be examined
TODO: An activity with a poorly designed DB that students should measure perf and improve, showing better perf?
SLIDE 12-1
– Obvious things like the fastest system with the most memory and fastest hard disk and the most free space along with a high performance network and operating system and optimized applications can help ensure we can handle the kinds of heavy traffic we expect. – a lot of the time much of the sluggishness of a database can be traced back to the application’s particular SQL queries.
– On the client side the focus is on generating a SQL query that the database can efficiently to obtain the correct answer quickly. It is also important that it utilize a minimum amount of resources at the server. – On the database server side, the focus is on responding to the client requests as fast as possible while using the least amount of resources.
There’s no magic here
– The data in a database is stored in files. As the data grows in size, additional space is allocated in increments as extends. – These data files are gathered into file groups or table spaces. These are a logical grouping of several data files stored data similar characteristics such as System information, User data, index data, etc. – Data buffer caches are also primary means of performance. They store the most recently accessed data blocks in memory.
- SQL itself maintains a cache containing the most recently executed SQL statements or procedures or functions.
- The database will often retrieve data from permanent storage (the disc) and stage it in main memory for fast access.
- This in-memory data cache is a lot faster than working with files.
-
Most of our optimizations aim to reduce input/output operations with the disk since it is a lot slower than the computer.
- Often the query optimizations are related to the optimal order of processing the steps of the query for the faster execution time
-
In distributed databases, the selection of sites and servers is important to minimizing network costs.
-
Some optimizations are actually handled by the DB itself - automatically - while others can only be done manually
- The first of these automatic optimizations is static query optimization, which is done when the SQL is “compiled” by the DB
- Other automatic optimizations occur at DB run time, since that’s is when the actual query sequences appear. This allows the DBMS to leverage the most up-to-date information about the database.
The DBMS maintains statistics about the database
- number & size of tuples
- previous average access times
- number of users accessing it
These statistics are used by the DBMS to determine the best access strategy.
How a DBMS processes SQL queries
SLIDE 3, 4
- Parse the SQL Query
- Usual parsing techniques are employed - break it down into smaller parts
- Rewrite the SQL in relational algebra expressions which are much easier to work with
- Apply transformation rules to those expressions to find equivalent, but more efficient, queries
- Devise a plan for the most efficient way to access the data, including the complex I/O operations required.
-
IMPORTANT
- A key technique for optimizing queries is to determine whether an equivalent access plan already exists in the SQL Cache
- If not, the optimizers evaluates the alternative plans and chooses one to use AND store in the SQL cache.
-
Run the Query
- Acquire needed locks
- Fetch the data into the data cache
- Execute transactions
-
Fetch the result and return it.
- Temporary table space may have been used
- Copy result into Client cache (if there is one)
- Initiate return of results to Client
What kinds of I/O plans might be used?
what can go wrong?
Lots of things can still slow it down
- slow system (CPU, network, hard disks)
- insufficient system memory (including caches)
- client load
- security (encryption, authentication)
- poorly-written application
About the importance of indexes in query processing
So how do databases find stuff so fast? Their indexes play a key (ha!) role
- full table scans are too slow, even with caches
- How would you even decide what would to put in the cache?
- help with searching, sorting, joins, and aggregate functions like
AVG - Just like the index in a book, a DB index is an ordering of one or more attributes
Slide 5, 6
We have an optional set of lecture notes on indexing and hashing
The types of decisions the query optimizer has to make
Relational algebra expressions sometimes have equivalents that are simpler. One job of the query optimizer is to find those equivalents and choose the least expensive one.
Query Opt
Once the query is represented in RelAlg expressions, the optimizer tried to find faster equivalent ones.
RelAlg expressions are equivalent if they produce the same set of tuples on all possible valid instances for the database.
Lets take a look at some of the equivalence rules employed.
SLIDE 7,8
SLIDE 9, 10
-
Selection operators are commutative
σθ1⋀θ2(E) = σθ1(σθ2(E))
-
Selection operators are commutative
σθ1(σθ2(E)) = σθ2(σθ1(E))
-
In a sequence of Projection operators, only lthe last one is needed
ΠL1(ΠL2 … (ΠLn(E))) = ΠL1(E)
- Selection can be combined with Cross products and theta joins
-
Theta joins are commutative
-
SLIDE 12 - 8 Natural joins are a special case of theta joins, so they are also commutative.
Theta joins are also associative sometimes:
where $\theta_{2}$ only involves attributes from $E_{2}$ and $E_{3}$.
-
Selection distributes over theta-join sometimes. When $\theta_{1}$ only involves attributes of $E_{1}$:
When $\theta_{1}$ only involves attributes of $E_{1}$ and $\theta_{2}$ involves only attributes of $E_{2}$:
- and several more.
How about some examples: SLIDE 11, 12, 13 This final version pushes the select down to operating on two smaller tables separately.
Evaluation plans
Evaluation plans specify the algorithm and parameters for each operation required, and how those operations are coordinated and ordered.
The cost differences can be quite large Let’s look at the example from the book:
SLIDE 14
write on the board
SELECT P_Code, P_Descript, P_Price, V_Name, V_State
FROM Product, Vendor
WHERE Product.V_Code = Vendor.V_Code AND
Vendor.C_State = 'FL';
- the
Producttable has 7,000 rows - the
Vendortable has 300 rows - 10 Vendors are in FL
- 1,000 products come from the vendors in FL
Without doing a query, the optimizer only knows 1 and 2.
Assuming all I/O costs are 1 and no indexes, this table shows two candidate access plans:
SLIDE 15
Discuss Plan A and Plan B:
Thus the optimizer would choose plan B.
What about indexes?
An Index is an orered array of index key values and row ID values (think of them as pointers). Indexes are typically used to speed up and facilitate data access.
Indexes are great, but you don’t want a lot of them.
- They take up disk space
- They require updating when data is modified
- They take up cache space
Instead of indexes on every column (NO!) try a few indexes, especially for
commonly queried composites (e.g., firstName,MI,lastName) and see how it goes.
Transaction oriented DB’s might be better with fewer indexes, and business information DB’s might have more.
More on indexes in Lecture 13.
Some common practices used to write efficient SQL code
Some suggestions from Burak Guzel and others:
1.”USE the cache, Luke!” MySQL will try to reuse results in the cache as much as possible. So you should try to make similar queries consistent to use the cache. However, if you call a nondeterministic function in the query, MySQL can’t depend on results being the same. So try to avoid this example from [Burak Guzel]:
// query cache does NOT work
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// query cache works!
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
2.When you’re only looking for a single, specific tuple, let SQL know [Burak Guzel]:
// do I have any users from Alabama?
// what NOT to do:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama'");
if (mysql_num_rows($r) > 0) {
// ...
}
// much better:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama' LIMIT 1");
if (mysql_num_rows($r) > 0) {
// ...
}
3.Whenever possible (and enforceable) use CHAR(n) instead of VARCHAR(n) (and
TEXT and BLOB) since fixed-size attributes are always faster.
4.Keep your primary keys integers whenever you can.
5.Don’t use DISTINCT when you have or could use GROUP BY. [MySQL]
6.Avoid wildcard characters at the beginning of LIKE clauses. If the first characters are specified, then the DB can use the index to speed up the LIKE search/matching. The worst case is “%ski%” which prevents any index help [Burak Guzel][MySQL].
7.Avoid SELECT * [Burak Guzel]:
// not preferred
$r = mysql_query("SELECT * FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// better:
$r = mysql_query("SELECT username FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// the differences are more significant with bigger result sets
8.Use Prepared Statements whenever you need to get input from the user [Burak Guzel]:
// create a prepared statement
if ($stmt = $mysqli->prepare("SELECT username FROM user WHERE state=?")) {
// bind parameters
$stmt->bind_param("s", $state);
// execute
$stmt->execute();
// bind result variables
$stmt->bind_result($username);
// fetch value
$stmt->fetch();
printf("%s is from %s\n", $username, $state);
$stmt->close();
}
-
When you know you will be joining two tables, make sure the attributes being used for that join are indexed! [Burak Guzel]
10.Transform conditional expressions to use literals (constants)[Coronel]
/* not good as a condition*/
... WHERE P_Price - 10 = 7;
/* better */
... WHERE P_Price = 17;
/* not good as a condition*/
... WHERE P_QOH < P_MIN AND P_MIN = P_REORDER AND P_QOH = 10
/* better */
... WHERE P_QOH = 10 AND PMIN = P_REORDER AND P_MIN > 10
- Always test equality conditions first - they’re the easiest to process. [Coronel]
- Numeric field comparisons are always faster than character, date, and NULL comparisons. [Coronel]
- Functions are convenient, but using them in a conditional can be very expensive especially for larger tables. [Coronel]
- When using multiple OR conditions, put the one most likely to be true first (this is a good thing to do in any programming language). [Coronel]
- Similarly, when using multiple AND conditions, put the one most likely to be false first (also a good thing to do in programming in general). [Coronel]
- Avoid the use of the NOT logical operator when possible.
- Use the
DESCRIBEto learn about tables andEXPLAINto understand - Don’t try to randomly select a tuple using ORDER BY Rand() (Burak Guzel])
// what NOT to do:
$r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");
// much better:
$r = mysql_query("SELECT count(*) FROM user");
$d = mysql_fetch_row($r);
$rand = mt_rand(0,$d[0] - 1);
$r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
Optional content
DBMS performance tuning
Caches
-
Data cache
- stores recent data retrieval results
- shared space among all database users
-
SQL cache
- stores the most recently executed SQL statements
- reasoning is for large multi-user databases many queries will be similar or the same
-
Sort cache
- temporary storage area used by
ORDER BYandGROUP BYoperations.
- temporary storage area used by
In-memory databases becoming popular with users who have extremely high-performance needs, and sometimes even short-term memory requirements (think stock trading)
RAID solutions for physical storage
Allocate separate disk volumes for specific tasks, to reduce contention.
- System data dictionaries - most frequently used space
- User data space - the more volumes here the better.
- index table space - should be separate from user and system data areas
- temporary table space
- Rollback table space
in addition, monitor usage to identify “hot spots” of database access and migrate those to their own volumes
Distributed DB’s
why move to distributed DB’s
- Globalization of business operation
- Advancement of web-based services
- Rapid growth of social and network technologies
- Digitization resulting in multiple types of data
- Innovative business intelligence through analysis of data
and some indirect reasons:
- for security and privacy reasons, keep the data near its source
- …
Examples
Bank with branches (from Garcia-Molina)
Each branch will keep a DB of accounts maintained in that branch. Customers can choose to bank at any branch, but will usually bank at “their” branch wheret their account data is stored.
A chain of stores
A chain may have many stores. Each store (or group of stores) has a database of sales and inventory. Ordering of replacement products when QOH reaches some minimum is handled by a central authority (DB). Each day the local DB’s are uploaded to the central one to enable optimal ordering batches as well as efficient distribution of goods when they arrive.
Distributed DB Advantages:
- Data are located near greatest demand site
- Faster data access and processing
- `SELECT * FROM DB WHERE condition’ could be cleverly split up across n processors.
- Growth facilitation
- Improved communications
- Reduced operating costs
- User-friendly interface
- Less danger of a single-point failure
- Processor independence
Disadvantages:
- Complexity of management and control
- Technological difficulty
- Security
- Lack of standards
- Increased storage and infrastructure requirements
- Increased training cost
- Costs incurred due to the requirement of duplicated infrastructure
What’s distributed
Can be the processing (as in Map Reduce) or the database itself or replicants of the database itself.
How does it work
- the front-end receives the query
- validates/decomposes it as usual
- further decompose into a set of I/O operations
- distributes the I/O’s
- distributes the processing of the I/O into results
- assembles the results
- presents the results
Distributed DB Architectures
SLIDE 12-18 SLIDE 12-19
Classification of DDBMS depending on the level of support for various types of databases
- Homogeneous: Integrate multiple instances of same DBMS over a network
- Heterogeneous: Integrate different types of DBMSs
- Fully heterogeneous: Support different DBMSs, each supporting different data model
More Attractions of Distributed DB
- distribution transparency
- management of physically dispersed DB’s as though they were centralized
- distribution can be very low, even rows at a time.
- You don’t know where it’s location (both good and bad news here)
- you just connect to something local and the DDBS takes care of the rest
- transaction transparency
- ensures DDB transactions maintain integrity and consistency (HARD!)
- transactions are only “complete” when ALL pending DDB systems involved have completed their parts
- SLIDE 12-20
multi-site multi-process operations can easily lead to inconsistencies and deadlocks - SLIDE 12-21
Makes use of the 2-phase commit protocol we discussed
- Failure & Performance transparency
- Performs like it was centralized
- resilient in the face of network outages
- Data Distribution and replication
- brief Secure Distributed Storage discussion
- Heterogeneity transparency
- You don’t realize there are different DB technologies in use across the DDB.
- Important for resiliency - homogeneous systems’ vulnerabilities