MongoDB - Aggregation Framework
admin
The Census examples are from the MongoDB Documentation and Jay Runkel of MongoDB. The mongodump of his database may be found in our Examples->MongoDB->dbs.
Motivation for the Aggregation Framework
We have all this data, we would like to do some analyses and ad hoc queries.
Remind folks of the Unix Pipeline concept (Thank you Doug McIlroy!)
Basic idea of the MongoDB Aggregation Framework
SLIDE 2
- A conveyor belt with three “stations”
- RED, BLUE, and GREEN squares are coming onto the conveyor
- $match filters out the GREEN squares
- $project changes the squares into circles
- $group counts the blue and red circles to determine the ratio of red to blue
Actual aggregate pipelines look like this: SLIDE 3
db.collection.aggregate([ { stage 1}, { stage 2}, {... stage N} ], {options})
Stages employ aggregation operators to perform actions like match and project,
and options include things like explain .
Example RDBMS Table and query
SLIDE 4
dirtBikes
| make | model | cc | priceNew |
|---|---|---|---|
| Yamaha | TTR50 | 50 | 1500 |
| Yamaha | TTR110 | 110 | 2100 |
| Honda | CRF50F | 50 | 1500 |
| Honda | CRF125 | 125 | 2999 |
| Honda | CRF125BW | 125 | 3399 |
| Kawasaki | KX65 | 65 | 3700 |
SELECT make, COUNT(*) as numModels
FROM dirtBikes
GROUP BY model;
Sample output
| make | numModels |
|---|---|
| Yamaha | 2 |
| Honda | 3 |
| Kawasaki | 1 |
Let’s create a similar mongoDB collection:
SLIDE 5
db.dirtBikes.insertMany([
{ make: "Yamama", model: "TTR50", cc: 50, priceNew: 1500 },
{ make: "Yamama", model: "TTR110", cc: 110, priceNew: 2100 },
{ make: "Honda", model: "CRF50", cc: 50, priceNew: 1500 },
{ make: "Honda", model: "CRF125", cc: 125, priceNew: 3000 },
{ make: "Honda", model: "CRF125BW", cc: 125, priceNew: 3400 },
{ make: "Kawasaki", model: "KX65", cc: 65, priceNew: 3700 },
]);
How would we do a similar query? Using a single stage aggregate pipeline:
Illustrate on board
db.dirtBikes.aggregate([
{
$group: {
_id: "$make",
num_models: {
$sum: 1,
},
},
},
]);
results in
{
"_id": "Kawasaki",
"num_models": 1
} {
"_id": "Honda",
"num_models": 2
} {
"_id": "Yamama",
"num_models": 2
}
Each stage consists of a pipeline operator and an expression. Pipelines are always an array of one or more stages. Stages are composed of one or more aggregation operators or expressions. Expressions may take a single argument or an array of arguments.
Here, $group is an operator in the first stage of this aggregation pipeline.
Operators always begin with $ and we can generally have as many stages as we
want.
Don’t confuse these aggregation operators with query operators.
The $make is a variable used within the aggregation. All variables begin with
a $.
Bookmark the Aggregation Pipeline Quick Reference
We can add more to the stage if we want.
SLIDE 6
db.dirtBikes.aggregate([
{
$match: {
priceNew: { $gt: 2700 },
},
},
{
$group: {
_id: "$make",
num_models: {
$sum: 1,
},
avgCost: {
$avg: "$priceNew",
},
},
},
]);
{
"_id": "Kawasaki",
"num_models": 1,
"avgCost": 3700
} {
"_id": "Honda",
"num_models": 2,
"avgCost": 3200
}
The aggregation model is a pipeline, similar to Unix pipes.
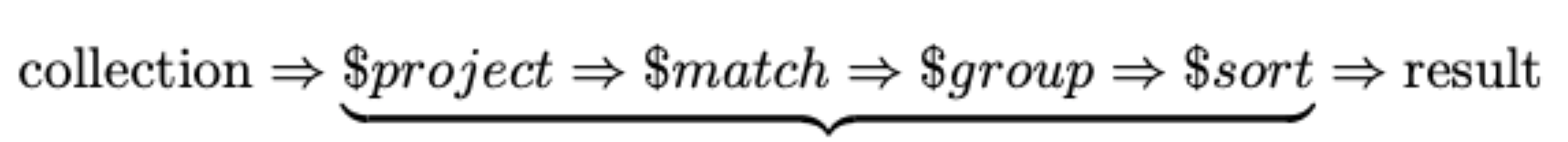
These pipeline stages can occur more than once and in any order you need.
SLIDE 7
| stage | action | Doc mapping |
|---|---|---|
$project |
selects values from the documents, even deep inside. | |
$match |
filter | |
$group |
aggregation, like sum, COUNT | |
$sort |
sorting | |
$skip |
skips results | |
$limit |
limit the results | |
$unwind |
flatten or denormalize the data | |
$out |
redirect output to a collection instead of a cursor | |
$redact |
limits documemts based on access permission info | |
$geonear |
limits documemts based on location info | |
Any number of stages in any order.
Let’s use Visual Studio Code and Compass
Let’s use $match to limit our search:
db.dirtBikes.aggregate([
{
$match: {
priceNew: {
$lt: 3500,
},
},
},
{
$group: {
_id: "$make",
num_models: {
$sum: 1,
},
avgCost: {
$avg: "$priceNew",
},
},
},
]);
{
"_id": "Honda",
"num_models": 3,
"avgCost": 2633.3333333333335
} {
"_id": "Yamaha",
"num_models": 2,
"avgCost": 1800
}
Switch to Census data (courtesy of Jay Runkel of MongoDB)
Let’s see what the general schema is:
db.cData.find()
db.cData.count()
db.cData.distinct("name")
Add a sort:
db.cData.distinct("name").sort()
Now let’s begin exploring aggregate pipelines
$match
db.cData.aggregate([
{
$match: {
region: "South",
},
},
]);
db.cData.aggregate([
{
$match: {
region: {
$ne: "South",
},
},
},
]);
$project - tailoring the pipeline flow
Getting rid of data you don’t need, renaming fields, reshaping the document, and doing calculations.
db.cData.aggregate([
{
$project: {
abv: 1,
},
},
]);
And let’s get rid of that annoying _id field.
db.cData.aggregate([
{
$project: {
_id: 0,
abv: 1,
},
},
]);
Selecting subfields (‘.’) force us to use quotes.
db.cData.aggregate([
{
$project: {
"center.coordinates": 1,
},
},
]);
db.cData.aggregate([
{
$project: {
"center.coordinates": 1,
_id: 0,
},
},
{
$limit: 10,
},
]);
You can do renaming too using another $
db.cData.aggregate([
{
$project: {
coords: "$center.coordinates",
_id: 0,
},
},
{
$limit: 10,
},
]);
Calculations using an aggregration pipeline
use sample_mflix
db.movies.aggregate(
[{
$match: {
rated: 'UNRATED'
}
}, {
$project: {
title: 1,
'tomatoes.viewer.rating': 1
}
}, {
$group: {
_id: 'avgRating',
averageViewerRatingOfUNRATED: {
$avg: '$tomatoes.viewer.rating'
}
}
}]
)
Example from MongoDB:
db.solarSystem.aggregate([
{
$project: {
_id: 0,
name: 1,
myWeight: {
$multiply: [
{
$divide: ["$gravity.value", 9.8],
},
86,
],
},
},
},
]);
Lots of other math operators
$group
The $group aggregate operator defines what field should be used to bundle
documents together.
db.cData.aggregate([{ $group: { _id: "$region" } }]);
Ok, but not too interesting. Add an accumulator:
db.cData.aggregate([
{
$group: {
_id: "$region",
regionCount: { $sum: 1 },
},
},
]);
This adds 1 to the new variable region_count for each _id every time a new
document matches.
And add a sort stage to add order.
db.cData.aggregate([
{
$group: {
_id: "$region",
regionCount: { $sum: 1 },
},
},
{ $sort: { regionCount: -1 } },
]);
How about total area by region:
db.cData.aggregate([
{
$group: {
_id: "$region",
regionCount: { $sum: 1 },
regionArea: { $sum: "$areaKM" },
avgStateArea: { $avg: "$areaKM" },
},
},
{ $sort: { regionCount: -1 } },
]);
The aggregate ignores fields in the $sum or $avg calculation that have an
unexpected datatype or are missing entirely.
Suppose we want to look at all the documents rather than grouping them by region.
// (Jay Runkel, MongoDB)
db.cData.aggregate([
{
$group: {
_id: null,
totalArea: { $sum: "$areaM" },
avgStateArea: { $avg: "$areaM" },
},
},
]);
When you group by null you’re asking MongoDB to group all the documents
together as one.
The $group stage has many other handy calculations like $max, $min,
$push, and $addToSet.
$project can do accumulations too, HOWEVER they operate on an array in the
document NOT on the document set as a whole.
use sample_restaurants
db.restaurants.aggregate([
{ $project: { _id: 0,
name: 1,
zipCode: "$address.zipcode",
maxScore: { $max: "$grades.score"},
minScore: { $min: "$grades.score"}} }
])
end of part 1
Compass Demo
$push
// (Jay Runkel, MongoDB)
db.cData.aggregate([
{
$group: {
_id: "$region",
totalArea: { $sum: "$areaM" },
avgArea: {
$avg: "$areaM",
},
numStates: {
$sum: 1,
},
states: {
$push: "$name",
},
},
},
]);
Here $push is just adding $name to a growing array named states. Note,
however, that $push doesn’t ensure that its resulting array is a proper set.
That is, it doesn’t guarantee that there will be only one occurrence of each
value in the resulting array. If you want a proper set as the result, you must
use $addToSet.
Two others aggregation expressions, $first and $last, are available, but
they only have meaning after the group is sorted. More on this later.
What if we want to access data that’s embedded in an array?
$unwind
Undoes an array into separate entries and $first to grab the first of a set of
results.
// (Jay Runkel, MongoDB)
db.cData.aggregate([
{ $unwind: "$data" },
{ $group: { _id: "$data.year", totalPop: { $sum: "$data.totalPop" } } },
{ $sort: { totalPop: 1 } },
]);
$unwind is used to reach into an embedded array of n elements inside a
document and create n documents each with a single field instead of the array,
each new document having one of the n elements.
We can use the $match stage to filter the documents for $unwind before
continuing to the next stage:
// (Jay Runkel, MongoDB)
db.cData.aggregate([
{ $match: { region: "South" } },
{ $unwind: "$data" },
{ $group: { _id: "$data.year", totalPop: { $sum: "$data.totalPop" } } },
]);
Now we want to show how we can do some calculations using the data the pipeline
returns, and leveraging $first and $last.
// find how state populations changed from census to census
// (Jay Runkel, MongoDB)
db.cData.aggregate([
{ $unwind: "$data" },
{ $sort: { "data.year": 1 } },
{
$group: {
_id: "$name",
pop1990: { $first: "$data.totalPop" },
pop2010: { $last: "$data.totalPop" },
},
},
{
$project: {
_id: 0,
name: "$_id",
delta: { $subtract: ["$pop2010", "$pop1990"] },
pop1990: 1,
pop2010: 1,
},
},
]);
and if we want to sort the output by delta we just add on a $sort:
// find how state populations changed from census to census
// sorted by the delta in populations
// (Jay Runkel, MongoDB)
db.cData.aggregate([
{ $unwind: "$data" },
{ $sort: { "data.year": 1 } },
{
$group: {
_id: "$name",
pop1990: { $first: "$data.totalPop" },
pop2010: { $last: "$data.totalPop" },
},
},
{
$project: {
_id: 0, // rename to "name"
name: "$_id",
delta: { $subtract: ["$pop2010", "$pop1990"] },
pop1990: 1,
pop2010: 1,
},
},
{ $sort: { delta: 1 } },
]);
$lookup
Roughly equivalent to SQL’s Left Outer Join, it allows you to compare documents in two collections from the same database. To each input document, the $lookup stage adds a new array field whose elements are the matching documents from the “joined” collection.
An example from the documentation:
db.orders.insert([
{ _id: 1, item: "almonds", price: 12, quantity: 2 },
{ _id: 2, item: "pecans", price: 20, quantity: 1 },
{ _id: 3 },
]);
db.inventory.insert([
{ _id: 1, sku: "almonds", description: "product 1", instock: 120 },
{ _id: 2, sku: "bread", description: "product 2", instock: 80 },
{ _id: 3, sku: "cashews", description: "product 3", instock: 60 },
{ _id: 4, sku: "pecans", description: "product 4", instock: 70 },
{ _id: 5, sku: null, description: "Incomplete" },
{ _id: 6 },
]);
// Now we use $lookup
db.orders.aggregate([
{
$lookup: {
from: "inventory",
localField: "item",
foreignField: "sku",
as: "inventory_docs",
},
},
]);
results in
{
"_id" : 1,
"item" : "almonds",
"price" : 12,
"quantity" : 2,
"inventory_docs" : [
{ "_id" : 1, "sku" : "almonds", "description" : "product 1", "instock" : 120 }
]
}
{
"_id" : 2,
"item" : "pecans",
"price" : 20,
"quantity" : 1,
"inventory_docs" : [
{ "_id" : 4, "sku" : "pecans", "description" : "product 4", "instock" : 70 }
]
}
{
"_id" : 3,
"inventory_docs" : [
{ "_id" : 5, "sku" : null, "description" : "Incomplete" },
{ "_id" : 6 }
]
}
$geo operators
We’ve mentioned the rich geospatial capabilities of MongoDB . Here’s an example where we want to compare the number of people living with 500Km of Hanover, NH in 1990, 2000, and 2010.
db.cData.aggregate([
{
$geoNear: {
near: { type: "Point", coordinates: [72.2887, 43.7044] },
distanceField: "dist.calculated",
maxDistance: 500000,
includeLocs: "dist.location",
spherical: true,
},
},
{ $unwind: "$data" },
{
$group: {
_id: "$data.year",
totalPop: { $sum: "$data.totalPop" },
states: { $addToSet: "$name" },
},
},
{ $sort: { _id: 1 } },
//{$out : "peopleNearDartmouth"}
]);
There are lots of these $geo operators.
$redact
The best way for a document to be protected from unauthorized viewing is to have the document protect itself.
The $redact operator can restrict access to documents based upon access
control information stored in the documents.
Here’s an example from the MongoDB docs:
Suppose we have a document:
{
"_id": 1,
"title": "123 Department Report",
"tags": ["G", "STLW"],
"year": 2014,
"subsections": [
{
"subtitle": "Section 1: Overview",
"tags": ["SI", "G"],
"content": "Section 1: This is the content of section 1."
},
{
"subtitle": "Section 2: Analysis",
"tags": ["STLW"],
"content": "Section 2: This is the content of section 2."
},
{
"subtitle": "Section 3: Budgeting",
"tags": ["TK"],
"content": {
"text": "Section 3: This is the content of section3.",
"tags": ["HCS"]
}
}
]
}
A user with access privileges for tags STLW and G wishes to see all the
documents for 2014. We store the user’s privileges into a variable and then
invoke a predefined query:
// store the user's privs
var userAccess = ["STLW", "G"];
// run the predefined query
db.forecasts.aggregate([
{ $match: { year: 2014 } },
{
$redact: {
$cond: {
if: {
$gt: [{ $size: { $setIntersection: ["$tags", userAccess] } }, 0],
},
then: "$$DESCEND",
else: "$$PRUNE",
},
},
},
]);
and here’s the result:
{
"_id": 1,
"title": "123 Department Report",
"tags": ["G", "STLW"],
"year": 2014,
"subsections": [
{
"subtitle": "Section 1: Overview",
"tags": ["SI", "G"],
"content": "Section 1: This is the content of section 1."
},
{
"subtitle": "Section 2: Analysis",
"tags": ["STLW"],
"content": "Section 2: This is the content of section 2."
}
]
}
$out
Use the $out operator as the last stage in a pipeline to create a new
collection in the current database. Otherwise, the results of a pipeline are
lost (after possibly displaying them).
The value for this operator is the quoted name of the new collection.
Be careful! This operator will happily overwrite an existing collection of the same name.
. . .
{ $out: 'myShinyNewCollection' }
. . .
Aggregation performance considerations
Some recommendations from MongoDB and from “MongoDB in Action”
Try to reduce the flow ASAP
Try to reduce the size and number of documents as quickly as possible in the pipeline.
Leverage indexes
$match and $sort can take advantage of indexes which could speed things up a
lot.
After you use any operator other than $match and $sort, indexes will
not be used.
So use $match as early in the pipeline as possible.
the aggregation framework’s explain function
The explain option can help developer’s understand how the pipeline is
actually getting its work done. It can tell you things like when indexes are
being used. You can add the explain after the pipeline definition. See the
example below.
Here’s a final example from Jay
Which US division has the fastest growing population density, given
- only considering states with more than 1M people
- only include divisions with more than 100K square miles
Here is the final aggregate. We’ll look at it here, and then we will look at it in Compass.
// bigquestion.js
db.cData.aggregate(
[
{ $match: { "data.totalPop": { $gt: 1000000 } } },
{ $unwind: "$data" },
{ $sort: { "data.year": 1 } },
{
$group: {
_id: "$name",
pop1990: { $first: "$data.totalPop" },
pop2010: { $last: "$data.totalPop" },
areaM: { $first: "$areaM" },
division: { $first: "$division" },
},
},
{
$group: {
_id: "$division",
totalPop1990: { $sum: "$pop1990" },
totalPop2010: { $sum: "$pop2010" },
totalAreaM: { $sum: "$areaM" },
},
},
{ $match: { totalAreaM: { $gt: 100000 } } },
{
$project: {
_id: 0,
division: "$_id",
density1990: { $divide: ["$totalPop1990", "$totalAreaM"] },
density2010: { $divide: ["$totalPop2010", "$totalAreaM"] },
denDelta: {
$subtract: [
{ $divide: ["$totalPop2010", "$totalAreaM"] },
{ $divide: ["$totalPop1990", "$totalAreaM"] },
],
},
totalAreaM: 1,
totalPop1990: 1,
totalPop2010: 1,
},
},
{ $sort: { denDelta: -1 } },
{ $limit: 1},
],
//, {"explain": true} // Just remove the "//" at the beginning of this line
);
{
"totalPop1990" : 42293785,
"totalPop2010" : 58277380,
"totalAreaM" : 290433.4,
"division" : "South Atlantic",
"density1990" : 145.623006858027,
"density2010" : 200.656604922161,
"denDelta" : 55.0335980641345
}