Galley uses a more complex file model that should lead to greater flexibility and performance.
Another problem with the linear file model is that a dataset may have a natural, parallel mapping onto multiple disks that is not easily captured by the standard cyclic block-declustering schemes. An example of this sort of dataset may be seen in the Flexible Image Transport System (FITS) data format, which is used for astronomical data. A FITS file is organized as a series of records, each of which is the same size and contains a key (which may be composed of multiple fields) and one or more data elements. While there is a fairly straightforward mapping of a FITS dataset onto a linear file (simply listing the records), it is not clear in what order the records should be listed. Furthermore, it is not clear that blindly striping this list across multiple disks is the optimal approach in a parallel file system. Rather, one could distribute the data across the disks using the keys and knowledge about how the dataset will be used to determine a partitioning scheme that results in highly parallel access.
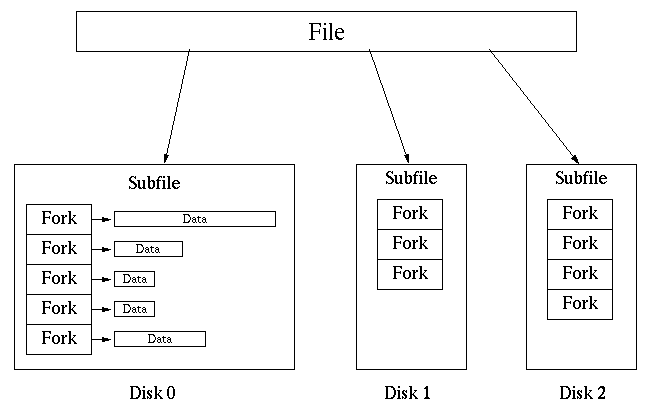
To address these problems, Galley does not automatically decluster an application's data. Instead, Galley provides applications with the ability to fully control this declustering according to their own needs. This control is particularly important when implementing I/O-optimal algorithms. Applications are also able to explicitly indicate which IOP they wish to access in each request. To allow this behavior, files are composed of one or more subfiles, each of which resides entirely on a single IOP, and which may be directly addressed by the application. This structure gives applications the ability both to control how the data is distributed across the IOPs, and to control the degree of parallelism exercised on every subsequent access.
The use of forks allows further application-defined structuring. For example, if an application represents a physical space with two matrices, one containing temperatures and other pressures, the matrices could be stored in the same file (perhaps declustered across multiple subfiles) but in different forks. In this way, related information is stored logically together but is available independently. As a result, an application (e.g., a visualization tool) that is only interested in one of the two pieces of data, can access the relevant data easily and efficiently.
In addition to data in the traditional sense, the availability of multiple forks also allows an application to store persistent, application-defined meta-data independently of the data proper. One example of a library that would be able to make use of multiple forks for metadata is a compression library similar to that described in a file 'compression.ps' once found at http://bunny.cs.uiuc.edu/CADR/pubs/. The library could store compressed data chunks in one fork and directory information in another.
Another potential use for forks can be seen in Stream*, a parallel
file abstraction for the data-parallel language, C*. Briefly, Stream*
divides a file into three distinct segments, each of which corresponds
to a particular set of access semantics. While the current
implementation of Stream* stores all the segments in a single file,
one could use a different fork for each segment. In addition to the
raw data, Stream* maintains several kinds of metadata, which are
currently stored in three different files: .meta, .first
, and .dir . In a Galley-based implementation of
Stream*, it would be natural to store this metadata in separate forks
rather than separate files.
Finally, a fork could also be used to store the code (Python, Java, standard object code, etc.) necessary to access the data stored in the other forks. This code could be linked with a user's application at runtime, or possibly loaded and run on the I/O node (see our white paper in ACM Operating Systems Review).