A word reduction is a series of words where each word is derived by deleting a single letter of the word before it, until there is only a single letter left. An example would be yeasty, yeast, east, eat, at, a. Any word that appears in such a sequence is called reducible. Because a word reduction has to get down to one letter, and the only one-letter words in English are a and I, we can restrict our attention to only those words containing these two letters.
We might like to know all of the reducible works in English, along with the longest such word. The program WordReduction.java is a way to answer these questions. It also demonstrates the use of sets, string manipulation, and file I/O, and so it is a good example for those reasons.
How might we go about solving this problem? Let's call a reducible word a "good" word. If we knew all of the good words shorter than our current word, we could try dropping each letter in the current word and seeing if it is one of the shorter good words. If so, we have found a new good word.
This program reads in all of the words in an online dictionary. The one that I use is one on the Mac, in the file /usr/share/dict/words. There are many other dictionaries online. Because we want to process the words in increasing order of length, we use a list of sets, where the the ith list contains a set of words of length i + 1. (No sense in having a list of words of length 0, right?)
We open the file using a FileReader and then use a Scanner to make it easy to process the words. The words in this dictionary appear one per line, and so we read a line, map the word to lower case, get its length, and then add it to the appropriate set.
The method dropLetter demonstrates the use of the substring method on strings. The string positions of string str are indexed from 0 to str.length()-1, just like arrays. We can call the charAt method to select a particular character (which we did in several of the testing programs). To take a substring, we give the start index and the index one beyond the final index. Therefore str.substring(1,2) has length 1 and str.substring(1,1) is the empty string.
We then process the strings in increasing order of length. We add i and a to the set goodWords of good words, and then work our way up from there (see the main method). We also go through and print the good words and the words that they derive from. Finally, we have a recursive method printReduction for printing out a reduction for any given word. Because the output is so large that it blows out the scrolling of the Console pane in Eclipse, we write it out to the file reductions.txt.
The HashSet and HashMap classes use a data structure called a hash table. The idea can be illustrated by how the Sears catalog store in West Lebanon used to keep track of catalog orders to be picked up. They had 100 pigeonholes behind the order desk, numbered 0 to 99. When a customer arrived, the clerk would ask the customers for the last two digits of the customer's phone number. Given a number, the clerk would look in the corresponding pigeonhole for the order form. Even if there were several hundred order forms in the system, each pigeonhole contained only a few forms, and the clerk could search through these quickly. This approach effectively split a set of hundreds of items into 100 sets of a few items each. The trick was to find a hash function that would assign each order form to a particular pigeonhole in a way that spread the order forms fairly evenly among them. The last two digits of the customer's phone number worked well for this purpose. The first two digits would have been a poor choice.
We can do a similar approach inside the computer. For a map, we want to use the key of the (key, value) pair to figure out where we are going. For a set, we use the object itself; in other words, the object is the key. So we'll talk about storing keys in the hash table, possibly with an associated value. In order to implement this idea, we need two things:
Now, if each key mapped to a distinct index in the table, we'd be done. That would be like all Sears customers having the last two digits of their phone numbers be unique. But they are not.
When multiple keys map to the same table index, we have a collision. Now, you might think that with 100 slots in the table, we'd have to get close to 100 keys inserted into the table before we'd be likely to have a collision. And you would be incorrect. Have you ever heard of the Birthday Paradox?
If you randomly select people, how many do you have to select before there is at least a 50% chance that at least two of them have the same birthday?
Again, you might think that the number is close to 365. Or maybe it's around half of 365: 183? Nope. It's much smaller than that. Much, much smaller. In fact, it's just 23. In terms of hashing, if we have 365 slots in the table and randomly insert keys, once we have inserted 23 keys, we have at least a 50% chance of a collision. Of course, for a 100% chance, we'd have to insert 366 keys.
"Randomly" distributed keys don't do what you might expect. If you "randomly" distribute n keys into a table of size n, your might expect to find one item in most of the slots, with very few empty slots. In fact, about n/e of the slots are empty (where e = 2.71..., the base of the natural logarithm). So over a third of the slots are expected to be empty! The expected length of the longest list is Θ(log n/ log log n). (To see how to compute these take CS 30.)
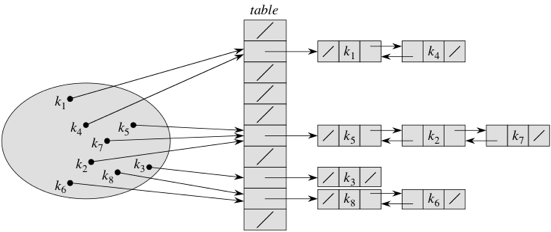
So how can we handle collisions? There are a couple of ways. The first one is called chaining. Instead of storing each element directly in the table, each slot in the table references a linked list. The linked list for slot i holds all the keys k for which h(k) = i. Here's the idea:
The keys are k1, k2, …, k8. We show each linked list as a noncircular, doubly linked list without a sentinel, and table slots without a linked list are null. Of course, we could make a circular, doubly linked list for each table slot instead, and have each table slot reference one such list, even if the list is empty. In some situations, especially when we only insert into the hash table and never remove elements, singly linked lists suffice.
How many items do we expect to look at when searching for a item? For unsuccessful search (it wasn't in the map or set), we would look at everything in the appropriate list. But how many elements is that? If the table has m slots and there are n keys stored in it, there would be n/m keys per slot on average, and hence n/m elements per list on average. We call this ratio, n/m, the load factor, and we denote it by α. If the hash function did a perfect job and distributed the keys perfectly evenly among the slots, then each list has α elements. In an unsuccessful search, the average number of items that we would look at is α. For a successful search we find the element (so always do 1 comparison), and look at about half of the other elements in the list. This means that for successful search you look at about 1 + α/2 items. Either way the running time would be Θ(1 + α). Why "1 + "? Because even if α < 1, we have to account for the time computing the hash function h, which we assume to be constant, and for starting the search. (Of course, if α < 1, then we cannot perfectly distribute the keys among all the slots, since a list cannot have a fraction of an element.)
Now, what if the keys are not perfectly distributed? Things get a little trickier, but we operate on the assumption of simple uniform hashing, where we assume that any given key is equally likely to hash into any of the m slots, without regard to which slot any other key hashed into. When we say "any given key," we mean any possible key, not just those that have been inserted into the hash table. For example, if the keys are strings, then simple uniform hashing says that any string—not just the strings that have been inserted—is equally likely to hash into any slot. Under the assumption of simple uniform hashing, any search, whether successful or not, takes Θ(1 + α) time on average.
Of course, the worst case is bad. It occurs when all keys hash to the same slot. It can happen, even with simple uniform hashing, but of course it's highly unlikely. But the possibility cannot be avoided. If an adversary puts n*m items into the table then one of the slots will have at least n items in it. He or she then makes those n items the data for the problem that you are dealing with, and you are stuck. (There is an idea called universal hashing, which basically computes a different hash code every time you run the program, so that data that is slow one time might be fast the next.)
Should the worst case occur, the worst-case time for an unsuccessful search is Θ(n), since the entire list of n elements has to be searched. For a successful search, the worst-case time is still Θ(n), because the key being searched for could be in the last element in the list.
How about inserting and removing from a hash table with chaining? To insert key k, just compute h(k) and insert the key into the linked list for slot h(k), creating the linked list if necessary. That takes Θ(1) time. How about removing an element? If we assume that we have already searched for it and have a reference to its linked-list node, and that the list is doubly linked, then removing takes Θ(1) time. Again, that's after having paid the price for searching. In fact, you can do just as well with a singly linked list if you keep track of the position before the one you are considering.
Note that if n gets much larger than m, then search times go up. How can we avoid this? The same way that we do for an ArrayList. When the table gets too full, we create a new one about double the size and rehash everything into the new table. What is "too full"? Java implementations typically start the table with size 11 and double the table size when α exceeds 0.75.
Everything is peachy now, right? Yes, except that we are now counting on the table having several empty slots. In other words, we're wasting lots of space, to say nothing of all the links within the lists. If memory is at a premium, as it would be in an embedded system or handheld device, we might regret wasting it.
The second way to handle collisions is called open addressing. The idea is to store everything in the table itself, even when collisions occur. There are no linked lists.
How can we store everything in the table even when there's a collision? One simple scheme is called linear probing. Suppose we want to insert key k and that h(k) = i, but slot i is already occupied. We cannot put key k there. Instead, we probe (look at) slot i + 1. If it's empty, put key k there. If slot i + 1 is occupied, probe slot i + 2. Keep going, wrapping around to slot 0 after probing slot m − 1. As long as n < m, i.e., α < 1, we are guaranteed to eventually find an empty slot. If the table fills, that is, if α reaches 1, then increase the table size and rehash everything.
Searching with linear probing uses the same idea as inserting. Compute i = h(k), and search slots i, i + 1, i + 2, …, wrapping around at slot m − 1 until either we find key k or we hit an empty slot. If we hit an empty slot, then key k was not in the hash table.
Linear probing is a nice idea, but it has a couple of problems. One is how to remove a key from the hash table. We cannot just remove it from its slot. Why not? Let's take the following situation. We insert keys k1, k2, and k3, in that order, where h(k1) = h(k2) = h(k3). That is, all three keys hash to the same slot, but k1 goes into slot i, k2 goes into slot i + 1, and k3 goes into slot i + 2. Then we remove key k2, which opens up a hole in slot i + 1. Then we search for key k3. What's going to happen? We probe slot i, see that it holds k1, not k3, and then probe slot i + 1. Because slot i + 1 is now empty, we conclude that k3 is not in the hash table. Wrong! How can we correct this error? We need some way to mark a slot as having held a key that we have since removed, so that it should be treated as full during a search but as empty during insertion. So if we remove many keys, we can end up with all (or almost all) of the "empty" slots being marked, and unsuccessful searches can go on for a very long time.
But there's another, more insidious, problem. It's called clustering. Long runs of occupied slots build up, increasing the average search time. Clusters arise because an empty slot preceded by t full slots gets filled next with a probability of (t + 1)/m. That's because the probability of hashing to any of the t slots is 1/m (and there are t of them), plus the next key could hash directly into that empty slot. And that's not the only way that clusters grow. Clusters can coalesce when one cluster grows and meets with another cluster.
There are various schemes that help a little. One is double hashing, where we take two different hash functions h1 and h2 and make a third hash function hʹ from them: h'(k,p) = (h1(k) + ph2(k)) bmod m. The first probe goes to slot h1(k), and each successive probe is offset from the previous probe by the amount h2(k), all taken modulo m. Now, unlike linear or quadratic probing, the probe sequence depends in two ways upon the key, and as long as we design h1 and h2 so that if h1(k1) = h1(k2) it's really unlikely that h2(k1) = h2(k2), we can avoid clustering. Again, we must choose our hash functions h1 and h2 carefully.
When we analyze open addressing, we use the assumption of uniform hashing, which says that the probe sequence hʹ(k, 0), hʹ(k, 1), hʹ(k, 2), …, hʹ(k, m − 1) used when searching or inserting is equally likely to be any permutation of the slot numbers 0, 1, 2, …, m − 1. In other words, each possible probe sequence is equally likely.
The result is that the average number of probes in an unsuccessful search or when inserting is approximately 1/(1-α). This number gets very large as α approaches 1. If the hash table is 90% full, then about 10 probes are needed. The average number of probes for a successful search isn't so hot, either: -(1/α) log(1/(1-α)). That's a little better than the number of probes for an unsuccessful search; when the hash table is 90% full, it comes to a little over 2.5 probes.
The problem now is how to compute the mapping from keys to spots in a table. This mapping is what the hash function does. A good hash function has three desirable properties:
Java computes hash functions in two steps. The first is to have every object have a hashCode() method, which returns an int. The default is often the address of the object in memory. Then we have to map this integer into an entry in the table. This is called the compression function.
A simple compression function is to take the hashcode modulo the table size, as we did above. This scheme works well when the table size is a prime number, but not so well otherwise. In that case, the book suggests computing ((ai + b) mod q) mod m, where i is the hashcode, q is a prime greater than m, and a and b are chosen at random between 1 and q − 1. (We can also let b be 0.) Fortunately for us, Java's library takes care of the compression function.
Java gives us the responsibility to come up with a good hashcode, however. In particular, if you define equals for an object, it is very important that you override hashCode so that two items considered equal have the same hashcode. That's because if you insert an item in the hash table and then search for it using something that is equal to the item, then you expect to find it. If the hashcodes are different you won't find it. You will be looking in the wrong slot.
So how can you compute hashcodes, particularly for composite objects (objects that have several instance variables or are strings or arrays, etc.)? A simple option is to sum all of the pieces, or sum the hashcodes of the pieces. But there's a problem with this approach: shuffling the order (say of a string) does not change the hashcode. It probably should! A better idea for computing the hashcode of what we can view as a tuple (x0, x1, …, xs − 1) is to pick a positive number a (the book suggests that 33, 37, 39, and 41 are good choices) and compute the polynomial x0as − 1 + x1as − 2 + x3as − 2 + ⋯ + x0. The book shows how to do this using Horner's rule, which basically means starting with a running total at x0 and for j = 1, 2, …, s − 1, multiplying by a and adding xj:
public int hashcode() {
final int a = 37;
int sum = x[0];
for (int j = 1; j < s; j++)
sum = a * sum + x[j];
return sum;
}The book also shows a way to use cyclic shifts for this purpose. For the curious, there is a lot of literature on hashing, including Donald Knuth's The Art of Computer Programming, Volume 3. (In my opinion, Knuth's multivolume set, The Art of Computer Programming, is outstanding.)