We often need to model entities that have connections between them. For example, we might want to know whether two people are friends. If we can identify a group of people all of whom are friends with each other that might tell us something about these people; for example, they might all be members of the same Greek house, or that they might constitute a terrorist cell.
For another example of entities with connections, think of a road map. Each intersection is an entity, and a connection is a road going between two intersections.
Sometimes we need to know more than just that there's a connection; there's some quantitative aspect of the connection that's important. For a road map, we might care not only that a road connects two intersections, but also about the length of the road. For another example, we might want to know, for any pair of world currencies, the exchange rate from one to the other.
Many years ago, mathematicians devised a nice way to model situations with many entities and relationships between pairs of entities: a graph. A graph consists of vertices (singular: vertex) connected by edges. Each edge connects one vertex to some other vertex. A vertex may have edges to zero, one, or many other vertices. Think of each vertex as representing an entity and each edge as a connection.
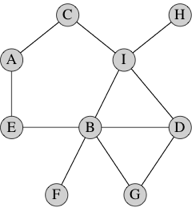
Here's a simple graph with 9 vertices and 11 edges:
Each vertex in this particular graph is labeled by a letter, though in general we can label vertices however we like, including with no label at all. Just to take an example, vertex A has two edges: one to vertex C and one to vertex E.
In some situations, we want directed edges, where we care about the edge going from one vertex to another vertex. Twitter's "follows" relationship is directed. Just because a follows b does not imply that b follows a. In other situations, such as the graph drawn above, the edges are undirected. Because the friendship relation is symmetric (in Facebook and real life), if we consider a graph in which vertices represent people and an edge between persons X and Y indicates that X and Y are friends, this graph would have undirected edges. Then again, a graph of who loves whom should be directed, since love is not always reciprocated. A graph with undirected edges is an undirected graph, and a graph with directed edges is a directed graph. We can always emulate an undirected edge between vertices x and y with directed edges from x to y and from y to x.
When we put a numeric value on an edge, say to indicate the length of a road, we call that an edge weight, "weight" being a generic term for the quantity that we care about. (Unless you're a civil engineer building elevated highways, you probably don't care how much a road actually weighs.) Edges can be weighted or unweighted in either directed or undirected graphs.
There are hundreds of computer applications where a graph is the appropriate ADT to use. These include road maps as mentioned before (vertices are intersections and edges are roads between them), airline routes (vertices are the airports and edges are scheduled flights between them), and computer networks (vertices are computers and edges represent network connections between them).
An example that we will see in Lab 5 is a graph of actors, with edges for those who have been in a movie together (edge labels hold movie names). A geekier example is a graph of authors of mathematical papers, with edges for coauthors (edge labels hold paper titles).
Given such a graph, there are many types of analyses we could do on it. Who's the most "popular" (has the most edges)? Who are mutual acquaintences ("cliques" where all vertices have edges to each other)? Who is a friend-of-a-friend but is not yet a friend?
And of course there is the Kevin Bacon game: someone has been in a movie with someone who has been in a movie ... who has been in a movie with Kevin Bacon — how many steps away are they (conjecture: usually at most 6)? In the geekier version, the center of the universe is the mathematician Paul Erdos, who coauthored hundreds of papers in his career. Mathematicians and theoretical computer scientists are characterized by their Erdos numbers. The highest known finite Erdos number is 13. Remarkably, there are a number of people who have both small Erdos numbers and small Bacon numbers (number = steps away). Dan Kleitman has total Erdos-Bacon number of 3 (Erdos 1, Bacon 2), but the Bacon number is due to a role as an extra in Good Will Hunting. Danica McKellar has an Erdos-Bacon number of 6, and is both a professional actress (The Wonder Years and West Wing) and wrote a published math paper (as well as supplemental math texts designed for teenage girls: Math Doesn't Suck, Kiss My Math, and Hot X: Algebra Exposed.)
You might sometimes hear other names for graph structures. Graphs are sometimes called networks, vertices are sometimes called nodes (you might recall that when I drew trees, I used the term), and edges are sometimes referred to as links or arcs.
A few more easy definitions. In mathematics, we write the name of an edge from vertex x to vertex y as (x, y). If the edge is undirected, then (y, x) is the same edge as (x, y), but not if the edge is directed. In an undirected graph, we say that the edge (x, y) is incident on vertices x and y, and we also say that x and y are adjacent to each other, and they are neighbors. In the above graph, vertices D and G are adjacent and edge (D, G) is incident on both of them. In a directed graph, edge (x, y) leaves x and enters y, and y is adjacent to x (but x is not adjacent to y unless the edge (y, x) is also present). The number of edges incident on a vertex in an undirected graph is the degree of the vertex. In the above graph, the degree of vertex B is 5. In a directed graph, the number of edges leaving a vertex is its out-degree and the number of edges entering a vertex is its in-degree.
If we can get from vertex x to vertex y by following a sequence of edges, we say that the vertices along the way, including x and y, form a path from x to y. A simple path is a path with no repeated vertices. The length of the path is the number of edges on the path. In the above graph, one path from vertex D to vertex A contains the vertices, D, I, C, A, with 3 edges; another path contains the vertices D, G, B, E, A, with 4 edges. Note that there is always a path of length 0 from any vertex to itself. A path from a vertex to itself containing at least one edge, and with all edges distinct, is a cycle. In the above graph, one cycle contains the vertices A, E, B, G, D, I, C, A; another cycle contains the vertices A, E, B, I, C, A. An undirected graph is connected if all pairs of vertices have some path between them.
The book gives a Graph interface. It has a number of useful methods. However, it is missing one thing that is often useful - retrieving a vertex that has a particular element value. The only way to do that here is to interate through the vertices and test them.
Here is a list of the methods in the Graph interface. Some of them throw an IllegalArgumentException if given a bad parameter, such as a vertex or edge not actually in the graph. We will discuss them in class.
Vertex<V> insertVertex(V element) inserts a vertex into the graph and returns a reference to its Vertex object. The parameter element is the information you want to store with the vertex, such as its name (in which case, the generic type V would be String).Edge<E> insertEdge(Vertex<V> u, Vertex<V> v, E element) throws IllegalArgumentException inserts an edge into the graph, once you have created its two vertices. The parameter element is the information you want to store with the edge. If there is already an edge (u, v) in the graph, insertEdge throws an IllegalArgumentException.Iterable<Edge<E>> incomingEdges(Vertex<V> v) throws IllegalArgumentException returns an iterable collection that contains all the edges that enter vertex v.Iterable<Edge<E>> outgoingEdges(Vertex<V> v) throws IllegalArgumentException returns an iterable collection that contains all the edges that leave vertex v.Vertex<V> opposite(Vertex<V> v, Edge<E> e) throws IllegalArgumentException returns the vertex at the other end of edge e from vertex v.Edge<E> getEdge(Vertex<V> u, Vertex<V> v) throws IllegalArgumentException returns the edge (u, v), or null if the graph contains no such edge.Vertex<V>[] endVertices(Edge<E> e) throws IllegalArgumentException returns a two-element array containing the vertices that edge e is incident on.void removeVertex(Vertex<V> v) throws IllegalArgumentException removes vertex v and all its incident edges from the graph.void removeEdge(Edge<E> e) throws IllegalArgumentException removes edge e from the graph.Iterable<Vertex<V>> vertices() returns an iterable collection that contains all the vertices in the graph.Iterable<Edge<E>> edges() returns an iterable collection that contains all the edges in the graph.int numVertices() returns the number of vertices in the graph.int numEdges() returns the number of edges in the graph.int inDegree(Vertex<V> v) throws IllegalArgumentException returns the in-degree of vertex v.int outDegree(Vertex<V> v) throws IllegalArgumentException returns the out-degree of vertex v.We can choose from among a few ways to represent a graph. Some ways are better for certain purposes than other ways. It's convenient to have a standard notation for the numbers of vertices and edges in a graph, and so we'll always use n for the number of vertices and m for the number of edges (either directed or undirected). It is often convenient to number vertices, and when we do, we number them from 0 to n − 1.
The run times of various implementations differ primarily on the operations getEdge, incomingEdges, outgoingEdges, vertices, and edges. (The number versions numVertices, numEdges, inDegree, and
outDegree usually return the size of the corresponding iterable collection.)
One simple representation is just an array or linked list of m edges, which we call an edge list. To represent an edge, we just give the numbers of the two vertices it's incident on. Each edge in the array is some object that includes the two vertex numbers. If the edge has a weight, the edge object also includes the weight.
Edge lists are simple, and they take only Θ(m) space, but if we want to find whether the graph contains a particular edge, we have to search through the array. If the edges appear in the array in no particular order, that's a linear search through m edges, taking Θ(m) time in the worst case. If there is not a separate list of vertices then finding all the vertices in the graph takes m time. Even if there is an list of vertices, deciding which edges are incident to a vertex takes m time. (Question to think about: How can you organize an edge list to make searching for a particular edge take O(lg m) time? The answer is a little tricky.)
For a graph with n vertices, an adjacency matrix is an n × n matrix of 0s and 1s, where the entry in row i and column j is 1 if and only if the edge (i, j) is in the graph. (Recall that we can represent an n × n matrix by an n-element array in which each entry references an array of n numbers.) If you want to indicate an edge weight, put it in the row i, column j entry, and reserve a special value to indicate an absent edge. (For example, -1 if all weights are non-negative. If a super-high weight indicates an absent edge, you can use Double.POSITIVE_INFINITY or Integer.MAX_VALUE.) Here's a unweighted, undirected graph and its adjacency matrix:
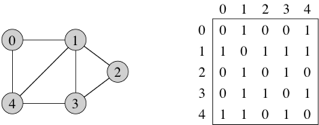
With an adjacency matrix, we can find out whether an edge is present in constant time, by just looking up the corresponding entry in the matrix. So what's the disadvantage of an adjacency matrix? Several things, actually. First, it takes Θ(n2) space, even if the graph is sparse: relatively few edges. In other words, for a sparse graph, the adjacency matrix is mostly 0s, and we use lots of space to represent only a few edges. Second, finding all of the edges takes Θ(n2) time. Third, if you want to find out which vertices are adjacent to a given vertex i, you have to look at all n entries in row i, taking Θ(n) time, even if only a small number of vertices are adjacent to vertex i.
For an undirected graph, the adjacency matrix is symmetric: the row i, column j entry is 1 if and only if the row j, column i entry is 1. For a directed graph, the adjacency matrix need not be symmetric.
Representing a graph with adjacency lists combines adjacency matrices with edge lists. For each vertex x, store a list of the vertices adjacent to it. We typically have an array of n adjacency lists, one adjacency list per vertex. We can store an adjacency list with an array (if we don't plan to insert or remove adjacent vertices) or a linked list (if we expect to insert or remove adjacent vertices). Here's an adjacency-list representation of the graph from above, using arrays:
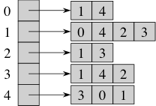
We can get to each vertex's adjacency list in O(1) time, because we just have to index into the array of adjacency lists. To find out whether an edge (x, y) is present in the graph, we go to x's adjacency list in O(1) time and then look for y in x's adjacency list. How long does that take in the worst case? Θ(d), where d is the degree of x, because that's how long x's adjacency list is. The degree of x could be as high as n − 1 (if x is adjacent to all other n − 1 vertices) or as low as 0 (if x is isolated, with no incident edges). In an undirected graph, y is in x's adjacency list if and only if x is in y's adjacency list. If the graph is weighted, then each element in each adjacency list includes the edge weight.
How much space do adjacency lists take? We have n lists, and although each list could have as many as n − 1 vertices, in total the adjacency lists for an undirected graph contain 2m items. Why 2m? Each edge (x, y) appears exactly twice in the adjacency lists, once in x's list and once in y's list, and there are m edges. For a directed graph, the adjacency lists contain a total of m items, one item per directed edge.
The textbook has another representation, the adjacency map, which the authors claim combines the best of adjacency lists and adjacency matrices. Instead of using an array or a linked list for each adjacency list, they use a map, implemented by a hash table. For a directed graph, each vertex has a hash table for its entering edges and a different hash table for its leaving edges, so that a directed graph has 2n hash tables altogether. For an undirected graph, each vertex has just one hash table, for a total of n hash tables. Now you can determine whether an edge (u, v) is present in O(1) expected time by going to u's hash table and, in O(1) expected time, seeing whether u's hash table has an entry for v.
The adjacency map representation is implemented in AdjacencyMapGraph.java. This representation implements the Graph interface. The constructor takes a boolean parameter that indicates whether the graph is directed (true) or undirected (false).
The AdjacencyMapGraph class is part of a large package called net.datastructures that is associated with the textbook; I've created a zip file of the entire package. To use it within Eclipse first create a new project. After you've uncompressed, drag the net folder to the src folder within the new project in the Package Explorer pane. This will add the 51 java files in the uncompressed folder into net.datastructures package in your Eclipse project. If you're going to use any of these classes, then you'll need to have the line
import net.datastructures.*;in your Java file.
You need to use at least two other files in net.datastructures if you're going to use AdjacencyMapGraph. The Vertex and Edge interfaces take generic types that say what information you're storing in a vertex or edge. Each interface has a single method: getElement().
We noted that a drawback to the AdjacencyGraphMap class (and all of the approaches we have discussed) is that finding the vertex with a particular label takes time proportional to the number of vertices in the graph. This is because you must iterate through a list to find the correct vertex. In sa10 you will created a subclass of AdjacencyMapGraph called NamedAdjacencyMapGraph. The NamedAdjacencyMapGraph class does everything that an AdjacencyMapGraph does, and it also maintains a map from vertex names (or whatever information you store with a vertex) to the Vertex object. In addition to the methods of AdjacencyMapGraph, it provides the following:
Vertex<V> getVertex(V name) returns the Vertex object corresponding to the name in the parameter, or null if there is no vertex with that name.boolean vertexInGraph(V name) returns a boolean indicating whether the graph contains a vertex with the name in the parameter.Edge<E> insertEdge(V uName, V vName, E element) throws IllegalArgumentException inserts an edge whose vertices have the names uName and vName into the graph. Like the insertEdge method of AdjacencyMapGraph, it throws an IllegalArgumentException if there is already an edge (u, v) in the graph.Edge<E> getEdge(V uName, V vName) throws IllegalArgumentException returns the edge whose endpoints are named by uName and vName, or null if the graph contains no such edge.It will also supply a constructor, override insertVertex(V element) to put the vertex name and the corresponding vertex into the map, and override removeVertex(Vertex<V> v) to remove the vertex name and corresponding vertex from the map.
In an AdjacencyMapGraph it is valid to have multiple vertices with the same name. However, in a NamedAdjacencyMapGraph this would cause problems, because it would not know which vertex to associate with a given name. Therefore the overridden version of insertVertex(V element) must check to make sure that the name is not already in the map, and throw an IllegalArgumentException if it is.
I find NamedAdjacencyMapGraph to be a convenient way to access vertices and their edges by the names of the vertices, rather than by the Vertex objects. It comes in particularly handy when you want to find a particular actor to compute his or her Bacon number.