Relationships
A graph represents a set of relationships among things. The vertices represent the things and the edges the relationships. There are gazillions of applications where a graph is the appropriate ADT to use. These include road maps (vertices are intersections and edges are roads between them), airline routes (vertices are the airports and edges are scheduled flights between them), the world-wide web (vertices are web pages and edges are hyperlinks), and networks (vertices are computers and edges represent connections). In society, vertices are people and edges their relationships — friend, partner, sibling, parent/child, etc. So a social network like Facebook can be represented by a graph with vertices for people who created Facebook pages and edges connecting people who have "friended" one another. Likewise people with Twitter accounts could be the nodes with an edge from A to B if A follows B.
Although we'll mostly focus on programming with graphs, I think it's helpful to look at them. One cool example: Western thinkers social network (the whole thing). I'll show some other graphs in class. There are a number of good (and freely available) graph visualization packages out there, including Cytoscape and Gephi.
{kind=link}
All the code files for today: AdjacencyMapGraph.java; Graph.java; RelationshipsTest.java
Graph interface
Note that there are two basic styles of graphs — one where the relationship is symmetric and the other where it is asymmetric. Facebook is a symmetric relationship — if A is B's friend, then B is A's friend also. Others are asymmetric. If A follows B on Twitter it does not imply that B follows A. In a graph of people where the relation is "child-of" it is never the case that if A is a child of B, then B is also a child of A. Unrequited love is another case where the relationship is asymmetric. Symmetric relationships lead to undirected graphs. An edge is between A and B. Asymmetrical relationships lead to directed graphs. An edge is from A to B, and there is no implication that there is also an edge from B to A (though there might also be one in some cases). There are also mixed graphs, where some edges are undirected and others are directed. A road graph with some one-way streets is an example.
The book gives an ADT definition, which as usual I have simplified a bit: Graph.java. Note that it is generic in terms of the types of things serving as vertices and edges. For example, V could be String if it's just a name, or an actual object if it's a whole Person instance. Likewise, we can associate different content with the edges, e.g., holding information about the type of relationship between two people, the distance between two cities, the capacity of a "tube", etc.
The interface has a number of useful methods:
- outDegree and inDegree: how many edges from and to a given vertex, respectively
- outNeighbors and inNeighbors: collections of the vertices connected from and to a given vertex
- hasEdge: whether or not one vertex is connected to another
- getLabel: return the label on the edge from one vertex to another
- insertVertex: add to the graph
- insertDirected, insertUndirected: from one vertex to another, with a label; or between (both directions) two vertices, with a label
- removeVertex, removeDirected, removeUndirected
Notice that undirected graphs (with symmetric / bidirectional edges) are basically treated as directed graphs, with pairs of opposite-directed edges. That is, an undirected edge between A and B is represented as an A-to-B edge plus a B-to-A edge.
Let's use this interface in a simple example of a social network with different types of relationships. RelationshipsTest.java
Given a graph, there are many types of analyses we could do on it. Who's the most "popular" (has the most in-edges)? Who are mutual acquaintences ("cliques" where all have edges to each other)? Who is a friend-of-a-friend but is not yet a friend? We'll look at some such problems over the next few classes (and the upcoming problem set).
Representation
We will use the following undirected graph to illustrate various options for representing graph structures, not worrying here about edge labels but just about who is "related to" whom:
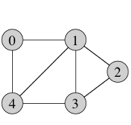
More generally, let n be the number of vertices (here 5) and m the number of edges (7, times 2 for the pairs), when we want to talk about the efficiency of various operations.
Edge List
What data structures can we use to represent a graph? The simplest is an edge list, just a list of neighboring pairs.
{ {0,1}, {0,4}, {1,2}, {1,3}, {1,4}, {2,3}, {3,4} }
Each edge object references its incident vertices (i.e., its endpoints). Here the pair is shown as a set to indicate undirected, but it could be an ordered pair instead. And the vertices could be kept in a separate list, or a set for faster lookup.
In general, insert is fast, but everything else is slow — might have to look through the whole list of edges, so O(m) time. At first glance removeVertex would seem to be fast — just remove it from the set. But part of the method is removing all edges incident to the vertex removed, so this will also take O(m) time.
Adjacency List
The obvious way to speed up the slow operations from the edge list structure is to have some way to get from a vertex to its neighbors. Traditionally the neighbors of a vertex are stored in a linked list, leading to the name adjacency list, but it could be any collection. For example, here's a representation of the out-neighbors for the graph from above:
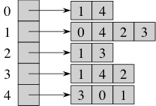
(Note that a representation of the in-neighbors would be exactly the same for an undirected graph, though might be different for a directed graph where not everything is symmetric. The book uses this for an efficient implementation of purely undirected graphs, but we allow "mixed" graphs with our interface here.)
How does this change run times? Clearly getting the neighbors is now very fast — just return the collection (or a copy of it). To copy it or actually iterate through the adjacency list for vertex v takes time O(degree(v)). Method removeVertex has the same run time. Method hasEdge(u,v) requires seeing if v is in the neighbors collection. This can be done in time O(degree(u)), if the neighbors collection is just a regular old list.
Adjacency Matrix
The hasEdge(u,v) method in an adjacency list takes more time than is really needed. To speed this up we can create an adjacency matrix, as long as the graph has no parallel edges. We combine this with the edge list structure. We number the vertices from 0 to n-1. We create an n x n matrix A where entry A[i][j] indicates whether or not there is an edge from vertex i to vertex j. (Note that for an undirected graph A[i][j] == A[j][i].)

(In Java, a matrix is the 2D version of an array, handled much the same way.)
Adjacency matricies make hasEdge(u,v) a Θ(1) operation — look in the matrix to see if there is an edge at the appropriate entry. However, finding neighbor lists now takes Θ(n) time, because we have to look through an entire row or column. And adding or removing a vertex requires rebuilding the entire matrix, which takes Θ(n2) time.
If we wanted to avoid numbering the vertices, and just using their values instead, we could replace the matrix with a Map, whose keys are pairs of vertices.
Implementation
We've developed a fairly lean implementation of the Graph interface, inspired by the maps used in the textbook but greatly simplified in order to focus on just the core neighbor relationships. See AdjacencyMapGraph.java.
It's much like the adjacency list representation described above, but now extended to keep edge labels too. So for each vertex, instead of the value in the map being just a list of neighboring vertices, it is itself a (nested) map from neighbor to corresponding edge label. We keep one such map for the out-neighbors (& edges) for a vertex, and another such map for the in-neighbors. E.g. for this map:
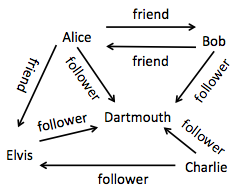
the out map would have:
{
"Alice" → { "Bob" → "friend", "Dartmouth" → "follower", "Elvis" → "friend" },
"Bob" → { "Alice" → "friend", "Dartmouth" → "follower" },
"Charlie" → { "Dartmouth" → "follower", "Elvis" → "follower" },
"Dartmouth" → {}
"Elvis" → { "Dartmouth" → "follower" }
}
and the in map would have:
{
"Alice" → { "Bob" → "friend"},
"Bob" → { "Alice" → "friend"},
"Charlie" → { },
"Dartmouth" → { "Alice" → "follower", "Bob" → "follower", "Charlie" → "follower", "Elvis" → "follower"},
"Elvis" → { "Alice" → "friend", "Charlie" → "follower" }
}
Then it's pretty easy to implement the interface by basically making the maps do all the work. The efficiency depends on that of the map implementation, which would be logarithmic with a balanced tree or expected constant time with a hash table. The first map lookup depends on the number of vertices, the second on the degree of the vertex in question. Removing a vertex still takes a bit of work, as we have to remove it from all the relevant maps. After finding the map for the vertex, its degree times the lookup of each of its neighbors times the map deletion cost. And since the edges aren't explicitly stored anywhere, getting their number actually requires summing the degrees.