Short Assignment 7 is due Monday.
Demonstrate the GUI in PS-3. Display the code of Editor.java.
Note two things:
JPanel objects are used to organize buttons. What is more, a JPanel
is used to hold the three button JPanels. We have discussed the FlowLayout layout manager. The GUI for PS-3 uses two
additional managers: GridLayout and BorderLayout. The first of these has
two parameters: the number of rows and number of columns. It lays components out on a grid of
this size. It is used for the JPanel holding the
three button panels to get them to line up in a vertical column.
A BorderLayout allows the user to put one thing at the top (NORTH), one at the bottom
(SOUTH), one on the right side (EAST), one on the left side (WEST), and one in the middle (CENTER).
The CENTER will expand to occupy all space not used by the other four. Here the JPanel
holding the three rows of buttons goes in the NORTH and the canvas goes in the CENTER.
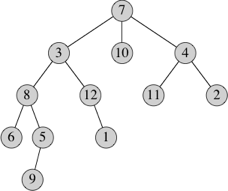
We use rooted trees to represent hierarchical relations. Here is an example of a rooted tree:
A tree is built up from nodes. The node at the top of the tree is the root; in our example, the root is node 7. Each node has zero or more children, which are also nodes. For example, node 4 has two children, which are nodes 11 and 2. An edge connects a node with its child, for example the edge (4, 11). Nodes with no children are external nodes or leaves (such as nodes 9 and 10), and nodes with at least one child are called internal nodes (such as node 4). A child has exactly one parent (except for the root, which has no parent); for example, the parent of node 11 is node 4. Nodes with the same parent are siblings, such as nodes 11 and 2. A path in a tree is a sequence of unique nodes such that each node in the sequence has an edge to the nodes before and after it. In our example, one path consists of nodes 6, 8, 3, 7, 4. If there is a path from the root to node y such that node x appears on the path, then node x is an ancestor of node y, and node y is a descendant of node x. For example, node 3 is an ancestor of node 5, and node 5 is a descendant of node 3. A subtree rooted at a node consists of all descendents of that node, including the node itself. The subtree rooted at node 3 comprises nodes 3, 8, 6, 5, 9, 12, and 1.
Here are some examples of relations that can be represented by trees:
Object.The book gives additional examples. We will see more examples as the course progresses.
The examples above have some cases where the order of children does not matter (the Java inheritance hierarchy, file systems, and organization charts). For an HTML document, however, the order does matter. In representing trees we end up imposing an order on children, whether it is important or arbitrary.
We will not use the tree code from our textbook, but feel free to read it. The book uses a different approach from what we have seen so far. We built our linked lists from Element objects, where Element is an inner class. We access the elements directly from within SentinelDLL or SLL and access fields with code such as current.next. We provide no access to Element objects from outside of the class, however. Instead, we have a current instance variable built into the class, or we provide an iterator. Java does the same thing.
In the textbook, they build up their lists, trees, graphs, etc. from Position objects. Position is an interface (in Position.java) with a single method: element. This method returns the data stored in the object. Their node classes for lists, trees, etc. implement the Position interface. They then let the user get a reference to one of these nodes via methods such as root in the Tree interface. Although root actually returns a reference to a Node object, its return type is Position.
Therefore, you can do only two things with a Position:
element on it to get the data saved within it.LinkedBinaryTree, which deal with positions. These methods will cast the Position to the correct type (after verifying that it is the correct type) and use it.We call Position an opaque type. You can pass it around and use it to mark where you are in a data structure, but you're not permitted to access anything within it. From a software engineering point of view, this is the way to go.
This partially protects against the user calling methods on the Position object (although if the user knows that the Position is really a LinkedTree node he or she can cast it and call the functions). However, this approach complicates the tree code and hides its basic simplicity. Therefore we implemented our own tree code. We do not implement code for general trees (although we could do so), but concentrate on the common special case of binary trees.
A binary tree is a rooted tree in which each node has zero, one, or two children. We designate each child as either a left child or a right child, even when it's an only child. Here are two different binary trees:
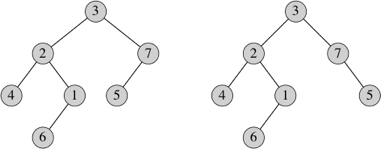
They differ only in that node 5 is a left child in the tree on the left, and it's a right child in the tree on the right.
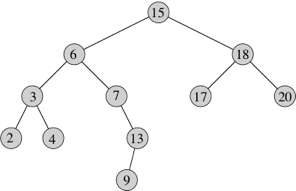
Binary trees come up in a multitude of applications: decision trees, expression trees, code trees (such as in Huffman encoding, which you'll be doing in Lab Assignment 4), and binary search trees. We'll see binary search trees later in the course, but the idea is that we store a value in each node, called the key, such that for every node x, the keys in its left subtree (the subtree rooted at its left child) are less than or equal to the key in node x, and the keys in its right subtree (the subtree rooted at its right child) are greater than or equal to the key in node x. Here is a binary search tree, with keys appearing inside the nodes:
Rather than having an inner class to represent the nodes and manipulating them via an outer class (as we did for linked lists), this time we make the tree nodes themselves more powerful and manipulate them from other classes. This code is in BinaryTree.java. The class BinaryTree has three instance variables:
left is a reference to the left child.right is a reference to the right child.data is the data stored in the node.The values of left or right are null if these children are absent. The book also keeps a reference to the parent node, which can be useful for certain applications. We will explore this further in sa7.
We access a binary tree through its root node. If we want to access a subtree, we access it through the root of the subtree. Thus, some of the methods in the BinaryTree class pertain to individual nodes, but we can always consider a node to be the root of a subtree.
BinaryTree classHere are the methods in the BinaryTree class. Although they are called on a BinaryTree object, many of them actually pertain to just the node at the root of a subtree, and that's what they're called on.
left and right to null.isInternal returns a boolean indicating whether the node is an internal node.isLeaf returns a boolean indicating whether the node is a leaf.hasLeft and hasRight return booleans indicating whether the node has left and right children, respectively.getLeft and getRight are getter methods for the left and right children.setLeft and setRight are setter methods for the left and right children.getValue and setValue are getter and setter methods for the data in the node.size returns the number of nodes in the subtree rooted at the node, including the node itself.height gives the height of the node, which is the number of edges in a longest path from the node down to a leaf. For example, in the binary trees above, the node with key 2 has height 2, and the node with key 4 has height 0.equals method determines whether two subtrees have exactly the same structure and the same data.fringe returns an ArrayList containing the data in all the leaves of the subtree rooted at the node, from left to right across the leaves. It calls the private helper method addToFringe. For the binary trees above, fringe would return an ArrayList with the values 4, 6, 5.toString returns a String that indents two spaces for each increase in the depth of a node: the number of edges in the path up to the root. If you turn your head sideways and look at the string returned by toString, you can see the structure of the binary tree. toString calls the private helper method toStringHelper.preorder, inorder, and postorder return lists (using the Java interface List) containing the data in the nodes of the subtree rooted at the node, according to the three types of traversal orders that we'll see later in the course.reconstructTree creates a binary tree, based on the results of preorder and inorder traversals of the tree. We'll see how this method works later in the course.You might have noticed that although the BinaryTree class includes a height method, it does not include a depth method. Think about why there is not enough information in a BinaryTree object, as defined, to write a depth method.
Notice that several of the methods are recursive. For example, the size method. That's because we can characterize the size of a subtree recursively:
The size of a subtree is 1 (for the root of the subtree), plus the size of its left subtree, plus the size of its right subtree. The size of an empty subtree is 0.
The size and height methods use a special ternary operator ? : in Java. (Ternary means that it takes three operands.) The first operand, appearing before the question mark, is a boolean expression. If the boolean expression evaluates to true, then the value of the operator is the second expression, between the question mark and the colon. Otherwise, the value of the operator is the third expression, which follows the colon. In the expression hasLeft() ? left.size() : 0 in the size method, if the call hasLeft() returns true, the expression's value is the value returned by calling left.size(). Otherwise, hasLeft() returns false, and the expression's value is 0.
Similarly, we can characterize the height of a node recursively:
The height of a leaf is 0. The height of an internal node is 1 plus the maximum heights of its children.
You might recall that the equals method must take a reference to Object as its parameter, no matter what class it appears in. Therefore, the first thing that equals does is make sure that other references a BinaryTree object. Generic types in Java are designed strangely, and although you would think that the first line should be
if (other instanceof BinaryTree<E>) {we have to put a question mark between the angle brackets instead. (I don't fully understand why, but it shows how difficult it is to design a programming language that is both easy to use and internally consistent.) After the instanceof check, we then cast other to a reference to BinaryTree<E>, this time using <E> and not <?>. The line @SuppressWarnings("unchecked") is another strange thing in Java; we could omit the line, but we'd get an annoying warning. Once we have cast the parameter, we have a complicated expression that checks for five requirements being met:
other does.other does.other are equal, according to the equals method on the generic type E.Notice how we rely on the || operator short-circuiting in the latter two tests. If hasLeft returns false, then do not call left.equals to check the left subtree, and ditto for the right subtree.
In the toStringHelper method, what's passed in is a string containing some number of spaces. These spaces precede each node in the subtree rooted at this. Each recursive call to toStringHelper increases the number of spaces by two. Although we usually think of processing the left subtree before the right subtree, in toStringHelper, we do the opposite so that when you look at the output with your head tipped to the left it looks like the structure of the binary tree. The toString method just gets things started off with an empty string.
We could have written the toStringHelper method in one line, using the ternary operator:
return (hasRight() ? right.toStringHelper(indent + " ") : "")
+ (indent + data + "\n")
+ (hasLeft() ? left.toStringHelper(indent + " ") : "");In the fringe method, we create an empty ArrayList and pass it to addToFringe. This ArrayList has data added to it if the node is a leaf, and it's passed to the left and right subtrees otherwise. We could have done something like we did for toString, but that would require appending two ArrayList objects.
The BinaryTree class has a main method as a driver. It starts by creating as tree this tree:
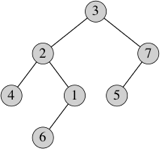
Then it exercises the size, height, and fringe methods. Next, it traverses the tree using preorder, inorder, and postorder traversals (again, we'll see what these are later on). With the preorder and inorder traversals, it creates a copy of the tree in tree1 and exercises equals method, which returns true. After making a change to the data in the right child of the root of tree1, it runs the equals method again, this time getting back false. Finally, it makes another copy of tree in tree2, changes the left child of the root in tree2 to have no left child, and runs the equals method again, once again getting back false.