Hash tables are fast (on average) and quite useful, but they have no
concept of order. If you iterate through a HashSet you get
items in the order that they appeared in the hash table, which is fairly
random. However, a TreeSet will return the elements in the
set in increasing order by compareTo. There are cases where
it is very useful to be able to do some other operations on a map that
depend on the ordering in the set. Such a map is called an ordered map.
The book suggests the following additional operations.
In any case above if no such entry exists the method returns null.
Note that this gives a way to interate through the map in order. Start with firstEntry(). Take the key k out of the entry and call higherEntry(k). Repeat. To iterate in reverse order use lastEntry and lowerEntry.
How do we represent an ordered map? Two obvious choices are a sorted array (or arraylist)
and a sorted doubly linked list. Either will implement the operations above in time Θ(1).
With the sorted array you have a fast get via binary search.
(If you have not seen binary search let me know!) Unfortunately, put and
remove are O(n) time, because you need to move elements after the desired position
to make room or close a hole. A doubly linked list has Θ(1) put and
remove (if you know where), but O(n) get. Actually, finding the place
to insert of delete in general will take O(n) time, also.
An obvious question is whether there is a way to combine the advantages of both data structures. The book gives two ways to do this. The first is skip lists, which we will come back to later in the term. The other is binary search trees, which we will cover next.
A binary search tree (BST) is a data structure combines the best features of a sorted array and a linked list. If we have our whole list, we can construct a tree that branches the same way that binary search does. Start with the middle element. Put it at the root of the tree. Pick the middle element of the left half and make it the left child of the root. Similarly the middle element of the right half is the right child of the root. (Write a list, demonstrate.)
We can now do binary search by following references. Compare the key that we are looking for with the root element. If they are equal we are done. If the key is less than the root recursively search the left subtree. (We don't have to do this recursively - we could just keep a pointer to which element we were at and change it to reference the left subtree.) If it is greater search in the right subtree. We will find it or reach an external node.
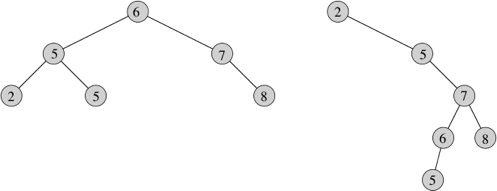
A binary search tree is organized, as the name suggests, in a binary tree, as shown here:
Here are two binary search trees with the same set of keys, shown inside the nodes, but with different structures. A binary search tree obeys the binary-search-tree property:
Let x be a node in a binary search tree. If y is a node in the left subtree of x, then the key in y is less than or equal to the key in x. If y is a node in the right subtree of x, then the key in y is greater than or equal to the key in x.
In the left tree above, the key of the root is 6, the keys 2, 5, and 5 in its left subtree are no larger than 6, and the keys 7 and 8 in its right subtree are no smaller than 6. The same property holds for every node in the tree. For example, the key 5 in the root's left child is no smaller than the key 2 in that node's left subtree and no larger than the key 5 in the right subtree.
The file BST.java shows how we work with a binary search tree. Unlike the BinaryTree class in BinaryTree.java, in our BST class, we separate the notion of the binary search tree from the nodes in the tree. We will see that we had to do so because, unlike in the BinaryTree class, the BST class will allow nodes to be removed, which means that we need a way to get to the entire binary search tree. (Why? Because if we have a reference to the root of the tree and then remove the root, how do we get to the remaining part of the tree? We need a class other than the class for nodes to maintain this information for us.)
Because we need to access both the binary search tree as a whole and individual nodes within it, we have an outer class BST<K,V>, with generic types K for keys within the nodes and V for the associated values, and a public inner class Node. As we'll see, from outside the BST.java file, we denote this inner class by BST<K,V>.Node, where K and V are the actual types used for the keys and values, e.g., BST<String,Integer>.Node.
Each Node object has the following instance variables:
left: a reference to its left childright: a reference to its right childparent: a reference to its parentkey: the key stored in the nodevalue: the value associated with the keyThe BST object has just two instance variables:
root: a reference to the Node object at the rootsentinel: a special Node object used to indicate an absent child or parent node. For example, the root's parent is the sentinel, and a leaf's children are both the sentinel. If the binary search tree is empty, then the root is the sentinel. Just as we did for SentinelDLL the sentinel will give us a way to do the
search loop with a single test rather than two tests.You might wonder why we bother with the sentinel node when we could just use null instead. Indeed we could (although we then could not do the trick
to speed up the search loop). But you'll also notice that many of the instance variables are protected, rather than private. That's because it can be convenient to define subclasses of BST for "balanced" binary search trees: binary search trees whose nodes all obey the property that the heights of their left and right subtrees are "close." Balanced binary search trees with n nodes typically have height Θ(lg n), which leads to fast operations on them. But we're getting ahead of ourselves. Let's just leave it for now that the sentinel node represents an absent child or parent.
As you can see, the BST constructor just makes one Node, the sentinel, and sets root to the sentinel. That's an empty binary search tree.
We often need to search for a key stored in a binary search tree. Besides the search operation (similar to the contains operation we saw for linked lists), binary search trees can support such queries as minimum, maximum, successor, and predecessor. We can implement each one in time O(h) on any binary search tree of height h.
We use the search method to search for a node with a given key in a binary search tree. It either returns a reference to a Node object with the key, or it returns null if no node in the binary search tree contains the key.
public Node search(K key) {
Node x = root;
sentinel.key = key; // So will find the item even if not in tree
// Go down the left or right subtree until either we hit the sentinel or
// find the key.
while (key.compareTo(x.key) != 0) {
if (key.compareTo(x.key) < 0)
x = x.left;
else
x = x.right;
}
sentinel.key = null; // Restore sentinel key value
// If we got to the sentinel, the key was not in the BST.
if (x == sentinel)
return null;
else
return x;
}The search starts at the root and traces a simple path downward in the tree. For each node x it encounters, it compares the parameter key with x.key. If the two keys are equal, the search terminates. If the parameter key is smaller than x.key, the search continues in the left subtree of x, since the binary-search-tree property implies that key could not be stored in the right subtree. Symmetrically, if key is larger than x.key, the search continues in the right subtree. The nodes visited form a simple path downward from the root of the tree, and thus the running time of search is O(h), where h is the height of the tree.
To see how the search method works on a binary search tree, consider this tree:
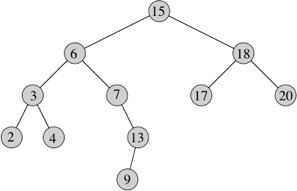
To search for the key 13 in the tree, we follow the path 15 → 6 → 7 → 13 from the root.
We can always find a node in a binary search tree whose key is a minimum by following left children from the root until we encounter the sentinel. The minimum method returns a reference to the node containing the minimum key in the subtree rooted at a given node x:
public Node minimum(Node x) {
// Keep going to the left until finding a node with no left child. That node
// is the minimum node in x's subtree.
while (x.left != sentinel)
x = x.left;
return x;
}The binary-search-tree property guarantees that minimum is correct. If a node x has no left subtree, then since every key in the right subtree of x is at least as large as x.key, the minimum key in the subtree rooted at x is x.key. If node x has a left subtree, then since no key in the right subtree is smaller than x.key and every key in the left subtree is not larger than x.key, the minimum key in the subtree rooted at x resides in the subtree rooted at x.left.
The code for the maximum method is symmetric:
public Node maximum(Node x) {
// Keep going to the left until finding a node with no right child. That node
// is the maximum node in x's subtree.
while (x.right != sentinel)
x = x.right;
return x;
}In the binary search tree above, the minimum key in the tree is 2, which is found by following children from the root. The maximum key 20 is found by following right children from the root.
Both of these methods run in O(h) time on a tree of height h since, as in search, the sequence of nodes encountered forms a simple path downward from the root.
Given a node in a binary search tree, sometimes we need to find its successor—the node with the next highest key— or its predecessor— the node with the next lowest key. In the case of equal keys, we'll see that we can think of the predecessor and successor in terms of an "inorder walk" of the tree. The structure of a binary search tree allows us to determine the successor of a node without ever comparing keys. The successor method returns the successor of a node x in a binary search tree if it exists, and null if x has the largest key in the tree:
public Node successor(Node x) {
if (x.right != sentinel)
// If x has a right subtree, the successor is the node in the right
// subtree with the minimum key.
return minimum(x.right);
else {
// Otherwise, the successor is the lowest ancestor of x whose left child
// is also an ancestor of x.
Node y = x.parent;
// Go up from x's parent toward the root until finding a left child or the
// root. x's successor is the parent of that first left child.
while (y != sentinel && x == y.right) {
x = y;
y = y.parent;
}
// Node y is the parent of the first left child on the path from x's
// parent to the root, or the root if we hit it. Return node y.
if (y == sentinel)
return null;
else
return y;
}
}We break the code for successor into two cases. If the right subtree of node x is nonempty, then the successor of x is just the leftmost node in x's right subtree, which we find by calling minimum(x.right). For example, the successor of the node with key 15 in the above figure is the node with key 17.
On the other hand, if the right subtree of node x is empty and x has a successor y, then y is the lowest ancestor of x whose left child is also an ancestor of x. In the above figure, the successor of the node with key 13 is the node with key 15. To find y, we simply go up the tree from x until we encounter a node that is the left child of its parent. The while-loop handles this case.
The running time of successor on a tree of height h is O(h), since we either follow a simple path up the tree or follow a simple path down the tree. The predecessor method, which is symmetric to successor, also runs in time O(h).
public Node predecessor(Node x) {
// If x has a left subtree, the predecessor is the node in the left
// subtree with the maximum key.
if (x.left != sentinel)
return maximum(x.left);
else {
// Otherwise, the predecessor is the lowest ancestor of x whose right child
// is also an ancestor of x.
Node y = x.parent;
// Go up from x's parent toward the root until finding a right child or the
// root. x's successor is the parent of that first right child.
while (y != sentinel && x == y.left) {
x = y;
y = y.parent;
}
// Node y is the parent of the first right child on the path from x's
// parent to the root, or the root if we hit it. Return node y.
if (y == sentinel)
return null;
else
return y;
}
}To insert a new node into a binary search tree, we use the insert method. It takes a key and a value, creates a new Node object z with this key and value, and inserts z into the BST object. It modifies the BST and some of z's instance variables in such a way that it inserts z into an appropriate position in the tree. The method returns a reference to the newly inserted Node.
public Node insert(K key, V value) {
Node z = new Node(key, value); // create the new Node
Node x = root; // Node whose key is compared with z's
Node xParent = sentinel; // x's parent
// Go down the BST from the root, heading left or right depending on
// how the new key compares with x's key, until we find a missing node,
// indicated by the sentinel.
while (x != sentinel) {
xParent = x;
if (key.compareTo(x.key) < 0)
x = x.left;
else
x = x.right;
}
// At this point, we got down to the sentinel. Make the last non-sentinel
// node be x's parent and x the appropriate child.
z.parent = xParent;
if (xParent == sentinel) // empty BST?
root = z; // then just the one node
else { // link z as the appropriate child of x's parent
if (key.compareTo(xParent.key) < 0)
xParent.left = z;
else
xParent.right = z;
}
return z;
}This figure shows how insert works:
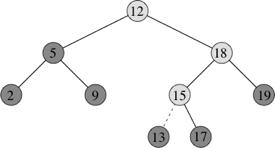
Just like the search method, insert begins at the root of the tree and x traces a simple path downward looking for a sentinel to replace with the new Node object z. Lightly shaded nodes indicate the simple path from the root down to the position where the new node is inserted. The dashed line indicates the link in the tree that is added to insert the node. The method maintains a Node reference y as the parent of x. After initialization, the while-loop causes these two references to move down the tree, going left or right depending on the comparison of z.key with x.key, until x equals the sentinel. The sentinel occupies the child position of y where we wish to place z. We need the trailing pointer y, because by the time we find the position where z belongs, the search has proceeded one step beyond the node that needs to be changed. The last few lines set the instance variables that cause z to be inserted and then return z.
Like the querying operations on binary search trees, the insert method runs in O(h) time on a tree of height h.
The overall strategy for removing a node z from a binary search tree has three basic cases but, as we shall see, one of the cases is a bit tricky.
z has no children, then we simply remove it by modifying its parent to replace z with the sentinel as its child.z has just one child, then we elevate that child to take z's position in the tree by modifying z's parent to replace z by z's child.z has two children, then we find z's successor y—which must be in z's right subtree—and have y take z's position in the tree. The rest of z's original right subtree becomes y's new right subtree, and z's left subtree becomes y's new left subtree. This case is the tricky one because, as we shall see, it matters whether y is z's right child.A word about the case in which z has two children. Many books, including our textbook and the first two editions of Introduction to Algorithms, treated this case differently and, at first blush, more simply. Instead of moving z's successor into z's position in the binary search tree, they took the information in z's successor (here, the key and value instance variables), copied them into z, and then removed this successor. Because z's successor cannot have two children (think about why), removing it will fall into one of the first two cases.
That approach turns out to be quite a bit simpler than what we're going to do. So why are we adding all the extra complexity? Because the code that uses the binary search tree might keep references to nodes within the tree. If the code to remove a node changes what's in a node, and if it removes a different node than the one requested, all heck can break loose in the rest of the program. So, instead, we will guarantee that if you ask to remove node z, then it is node z and only node z that is actually removed, and all references to all other nodes remain valid.
The code for removing a given node z from a binary search tree organizes its cases a bit differently from the three cases outlined previously by considering the four cases shown here:
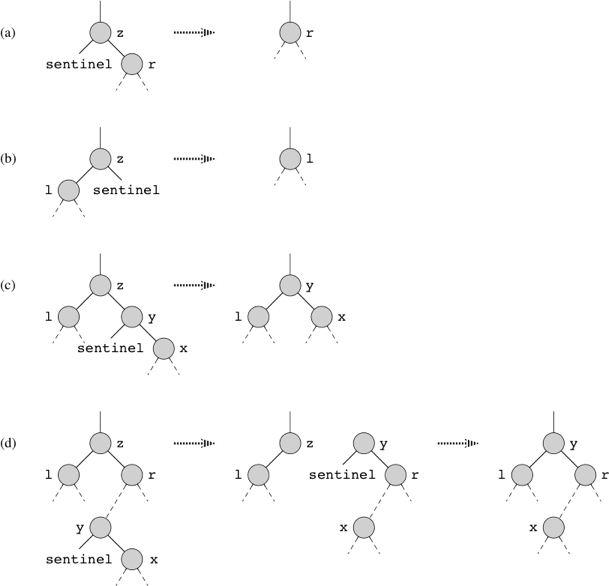
If z has no left child (part (a) of the figure), then we replace z by its right child r, which may or may not be the sentinel. When z's right child is the sentinel, this case deals with the situation in which z has no children. When z's right child is not the sentinel, this case handles the situation in which z has just one child, which is its right child.
If z has just one child, which is its left child l (part (b) of the figure), then we replace z by its left child.
Otherwise, z has both a left child l and a right child r. We find z's successor y, which lies in z's right subtree and has no left child but could have a right child x. We want to splice y out of its current location and have it replace z in the tree.
If y is z's right child (part (c)), then we replace z by y, leaving y's right child x alone.
Otherwise, y lies within z's right subtree but is not z's right child (part (d)). In this case, we first replace y by its own right child x, and then we replace z by y.
In order to move subtrees around within the binary search tree, we use a helper method, transplant, which replaces one subtree as a child of its parent with another subtree. When transplant replaces the subtree rooted at node u with the subtree rooted at node v, node u's parent becomes node v's parent, and u's parent ends up having v as its appropriate child.
protected void transplant(Node u, Node v) {
if (u.parent == sentinel) // was u the root?
root = v; // if so, now v is the root
else if (u == u.parent.left) // otherwise adjust the child of u's parent
u.parent.left = v;
else
u.parent.right = v;
if (v != sentinel) // if v wasn't the sentinel ...
v.parent = u.parent; // ... update its parent
}This method is protected because subclasses might need to call it, but code using the BST class should not need to know about it.
The first two lines handle the case in which u is the root. Otherwise, u is either a left child or a right child of its parent. The last two cases of the if-ladder take care of updating u.parent.left if u is a left child or u.parent.right if u is a right child. We allow v to be the sentinel, and the last two lines update v.parent if v is not the sentinel. Note that transplant does not attempt to update v.left and v.right; doing so, or not doing so, is the responsibility of transplant's caller.
With the transplant method in hand, here is the method that removes node z from a binary search tree:
public void remove(Node z) {
if (z.left == sentinel) // no left child?
transplant(z, z.right); // then just replace z by its right child
else if (z.right == sentinel) // no right child?
transplant(z, z.left); // then just replace z by its left child
else {
// Node z has two children.
Node y = minimum(z.right); // y is in z's right subtree, and y has no left
// child
// Splice y out of its current location, and have it replace z in the BST.
if (y.parent != z) {
// If y is not z's right child, replace y as a child of its parent by
// y's right child and turn z's right child into y's right child.
transplant(y, y.right);
y.right = z.right;
y.right.parent = y;
}
// Regardless of whether we found that y was z's right child, replace z as
// a child of its parent by y and replace y's left child by z's left
// child.
transplant(z, y);
y.left = z.left;
y.left.parent = y;
}
}The remove method executes the four cases as follows. The first two lines handle the case in which node z has no left child, and the next two handle the case in which z has a left child but no right child.
The remainder of the method deals with the remaining two cases, in which z has two children. We first find node y, which is the successor of z. Because z has a nonempty right subtree, its successor must be the node in that subtree with the smallest key; hence the call to minimum(z.right). As we noted before, y has no left child. We want to splice y out of its current location, and it should replace z in the tree. If y is z's right child, then the last three lines replace z as a child of its parent by y and replace y's left child by z's left child. If y is not z's right child, the lines
// Splice y out of its current location, and have it replace z in the BST.
if (y.parent != z) {
// If y is not z's right child, replace y as a child of its parent by
// y's right child and turn z's right child into y's right child.
transplant(y, y.right);
y.right = z.right;
y.right.parent = y;
}replace y as a child of its parent by y's right child and turn z's right child r into y's right child, and then the last three replace z as a child of its parent by y and replace y's left child by z's left child.
Each line of remove, including the calls to transplant, takes constant time, except for the call to minimum. Thus, remove runs in O(h) time on a tree of height h.
BST classThe code in BSTTest.java tests the BST class. We have not discussed the toString method, but it is similar enough to how the toString method in BinaryTree.java operates that you should be able to figure out how it works.