Pattern matching
Our goal is to build a mechanism for pattern matching in strings. You might have already used various specifications of patterns in different contexts. For example, on the Unix command line you can say "ls *.java" to list all file names with extension ".java"; the "*" means "match as many characters as you need to". Or you can say "ls notes/[1-3]/*.java" to list all such file names in subdirectories named "1", "2", or "3" in the "notes" directory. Patterns are also often used to validate (and extract pieces of) input in web forms. For example, for an email address, match some characters, then an "@" sign, then some characters, then a ".", etc.; for a date of the form "01/20/2010", match two numbers then a slash then two numbers then a slash then four numbers.
For lots more on formal languages and the strings they accept, take CS 39. We'll work here with a representation and implementation of patterns using finite automata, which allow us to recognize so-called
All the code files for today: DFA.java; NFA.java
- Regular expressions
- Finite automata
- Deterministic finite automata
- Nondeterministic finite automata
- Glossary
Regular expressions
Most programming languages support some form of regular expression (regex) matching, either built-in or in an extra library. We've used Java's version in the String.split method (e.g., splitting by whitespace / non-word characters for various text processing applications).
Different regex libraries sometimes have different syntax and conventions, and reading a big hairy regex is a serious pain. But it's useful to understand the basic constructs and be able to devise simple ones. (Browse the Java tutorial for more detail. Note that you shouldn't need to develop big hairy regexes for common tasks, as that's been repeatedly done.) Basic ways to build up a regex:
| operation | meaning | example |
|---|---|---|
| character | match that character next | "a" matches "a" :) |
| concatenation: R1 R2 | one after the other | "cat" matches "c" then "a" then "t" |
| alternative: R1 | R2 | one or the other | "a|e|i|o|u" matches any of those vowels |
| grouping: (R) | establishes/clarifies order; allows reference/extraction | "c(a|o)t" matches "cat" or "cot", as does "(cat)|(cot)", but not "(ca)|(ot)" |
| character classes: [c1c2...] and [^c1c2...] | alternative characters and excluded characters | [abc] matches "a" or "b" or "c" while [^abc] matches any but those |
| repetition / Kleene star: R* | matches zero or more times | "ca*t" matches "ct" or "cat" or "caat" or "caaat" or ... |
| non-zero repetition / Kleene cross: R+ | matches one or more times | "ca+t" matches "cat" or "caat" or "caaat" or ... |
There are also various metacharacters: start (^) and end ($) of the line; any character (.); shorthands for character classes such as word (\w), nonword (\W), whitespace (\s), numeric (\d), etc. Note that since backslash means something in quotes in Java, we must backslash the backslash, e.g., "\\w". Ugh.
Note that the star in Unix is different, directly meaning "anything, 0 or more times", which would be written ".*" in a more standard regex language.
The question for today is how to implement a regular expression matcher. Graphs to the rescue!
Finite automata
A finite automaton (plural: "automata") can be thought of as a rule describing how to scan a sequence of input symbols, one at a time, and decide whether the sequence satisfies the rule (it accepts the sequence) or not (it rejects it). Such an ability is at the heart of common pattern-matching tasks, such as those described above.
One analogy for a finite automaton is a road map in which there are a number of cities connected by one-way streets. We start at a particular city, can travel along the streets (obeying the one-way signs!), and hope to arrive at one of a number of destination cities. However, to travel along a particular street, we have to produce the right token at its toll booth. We start with a tube of tokens. At each city, we take the top token in the tube, and if there is a road whose toll booth accepts that token, we pay up (use the token and advance to the next one) and traverse that road to the next city. If we ever get to a point where there is no road that will take our next token, we are stuck in that city, and lose the game. Otherwise we will eventually run out of tokens. If, at that point we are in one of the final states, we win; otherwise, we lose.
With this intuition in mind, we can see that a finite automaton (FA) can be represented as a digraph with edge labels indicating the required tokens. The set of possible labels is called the alphabet, and it is customary to call the vertices states and the labeled edges transitions. A single state is the start state (as with BFS, etc.), and a set of states are the desired final states. A sequence of labels that traverse edges from the start state to a final state is accepted, while other sequences are rejected. The power of a finite automaton comes from the types of sequences it can accept.
Finite automata may be deterministic or non-deterministic; a deterministic finite automaton (DFA) has exactly one choice for each possible symbol at each state, while a nondeterministic one (NFA) may have zero, one, or more than one.
Following are a simple DFA and a simple NFA, each of which accepts any sequence of 0s and 1s that starts with a 0. (It turns out that any NFA can be converted to a DFA, but as you see here, the NFA is more compact.)
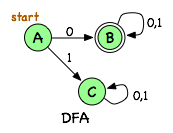
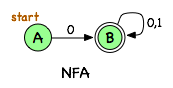
The start state is indicated with text; the final states have double circles. Transition arrows labelled "0, 1" are a shorthand for two transitions that have the same endpoints, but different labels. These can be viewed as multiple edges, or multiple labels on the same edge.
Deterministic finite automata
A simple DFA pattern matcher: DFA.java. The code stores the transitions explicitly in a Map, rather than by way of an explicit Graph, but the idea is the same — the graph way of thinking has shaped the way we approach this. (Note that the representation of edges in this Map is slightly different than in our Graph implementation — why?) Also note that we don't even have to keep track of all the states (we could get them as the keySet of the Map if we wanted) — just the start state and the end states.
A traversal through a DFA is cut and dried (deterministic) — there's only one choice for what to do, based on the current token. So we just repeatedly follow transitions for an input sequence, beginning at the start state. Return true if the sequence drives the DFA to a final state (i.e., the sequence is accepted), or false otherwise.
The main sets up the example DFA above by defining the states (following the name with ",S" for the start state and ",E" for the end states) and transitions (from, to, characters allowed). It then tests some that should return true and some that should return false.
Nondeterministic finite automata
A traversal through an NFA requires choosing which transition to take whenever there is more than one transition that allows the character at hand. (It returns false when none does.) An NFA accepts its input if any path from the start state, following edges labeled by the corresponding input symbols, leads to some final state.
As another example, here's an NFA that accepts sequences of 0s and 1s that contain two consecutive 0s, two consecutive 1s, or both.
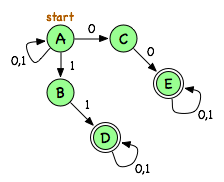
There are different ways to do matching in an NFA. One approach is to convert it to a DFA, but that can actually blow up (exponentially). Another way is kind of like breadth-first search. Rather than keeping track of a single state that we're in (having matched some characters so far), keep track of all the possible states. Then follow all the appropriate transitions out of each of them, for each additional character. We could do this exactly like with BFS, but since all paths are proceeding in "parallel" (how many characters have been matched), it's more traditional to expand them all at the same time. The ripples in the pond get bigger simultaneously, rather than sequenced through a queue.
That's the approach taken in NFA.java. The key differences from DFA are noted. In particular, since a state can have multiple transitions for a given character, the Map structure is now from a state and character to a list of states. And then the matching algorithm maintains a list of the current states reached so far, initially just the start state, and then for each letter stepping from each current state to each next state via transitions for that character. At the end (after walking through the whole input string), we check if any of the states is an end state.
There exist procedures to convert regular expressions to finite automata. While we won't go through them in detail here, you can kind of see how they'd work.
- concatenation: one state following another
- alternative: two possible transitions following one
- Kleene star: self loop
- Kleene cross: one state to force the non-zero part, with transition to Kleene star state
Cranking through this kind of conversion tends to produce an NFA that's bigger than it needs to be, so then it can be simplified in postprocessing.
Glossary
There's some jargon here, so I've collected some of the main terms with a high-level description of each (thanks to Lily Xu '18).
- regular expression (regex)
- A way to write a string-matching pattern, in terms of individual characters to match one-by-one, along with concatenation, alternative, grouping, and repetition.
- finite automaton (FA)
- A graph-based representation of how to scan a string, one character at a time, and decide whether or not it is "acceptable". The vertices represent choice points, and the edge labels are characters, such that a string corresponds to a path through the graph.
- deterministic finite automaton (DFA)
- An FA in which for each vertex there is exactly one edge for each symbol.
- nondeterministic finite automaton (NFA)
- An FA with 0, 1, or more than one edge for each symbol from each vertex.
- state
- A vertex in an FA graph, representing a choice point. One state is labeled the "start" state; this is where the matching begins. One or more states are labeled the "final" states; if the matching ends there (after all input characters), then the string is accepted (considered a match), else it is rejected.
- transition
- An edge in an FA graph, labeled with a character. The next character in the input string must match the label in order to proceed to the next state.