Lab Assignment 6 is due Monday, March 7.
Short Assignment 12 is due Friday, February 26.
The program in Kalah.zip demonstrates how a simple program can play a complex game surprisingly well. Kalah is a very old African game played on a board that looks like an egg carton with big depressions at either end. Each player has six "pits" on his or her side of the board, and one "kalah" at the left end (from that player's view). The board looks something like:
A move consists of picking up all the stones in one of your pits and dropping them around the board in a clockwise manner. You drop stones into your pits, your kalah, and your opponent's pits until you run out of stones. You skip over your opponent's kalah. If the last stone dropped ends up in your kalah you move again.
If the last stone dropped ends up in an empty pit on your side of the board opposite a non-empty pit on your opponent's side, then you captured the stones in that pit. You move all of those stones plus the capturing stone immediately to your kalah.
If it is your turn and there are no stones left on your side of the board all stones on your opponent's side are moved to his or her kalah and the game ends.
Demo the game.
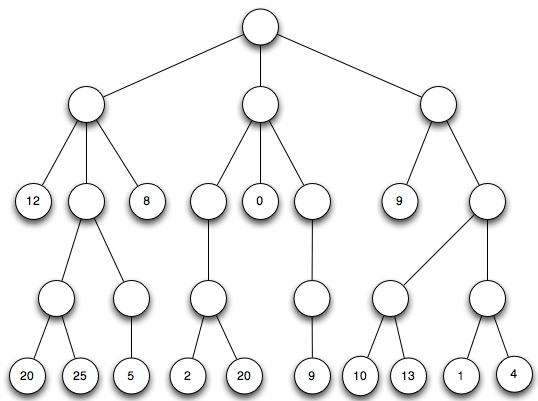
In class I will demonstrate on this example from the W12 final exam.
Evaluate from the bottom up, maximizing at even levels and minimizing at odd levels. Show that the maximum choice is the best move for the root. Do again, always maximizing and negating.
We look at the pickMove method from the class ComputerKalahPlayerGTS.
This program looks ahead a fixed number of moves, where a move is considered to be "the other person's turn". Therefore if you get to move again because the last stone dropped was in your kalah it does not count as a new turn.
The static evaluation function is very simple - the stones in your kalah minus the stones in your opponent's kalah. It is crude, but easy to do and works well.
The evaluation function is a bit more complex than in Chips, but uses the same idea. It goes through all the moves and picks the best, calling itself recursively if we are not yet at maximum search depth and doing a static evaluation if we are at maximum search depth. It always maximizes, but it negates the score returned by the opponent in the recursive call. (Good scores for my opponent are bad scores for me, and vise versa.)
A couple of points are worth noting. First, outcomes from games played to completion are multiplied by 100. This is to make the program pick a certain one-point win over a move that is estimated to win by more, but is not certain. Similarly a certain one-point loss will be avoided if another course of action is not certain to lose.
Another point is how the depth is adjusted. The depth only is decreased when the player who is moving changes. Therefore a whole series of "move again" moves where the last stone ends up in your kalah count as a single move.
A third point is that we use -Integer.MAX_VALUE instead of
Integer.MIN_VALUE to represent negative infinity. This is because
negating Integer.MIN_VALUE gives back Integer.MIN_VALUE,
due to overflow. (Try it in DrJava!)
Finally, note that a class KalahMove is used to return a (value, move) pair. This is necessary because Java allows us to only return one value from a method and all parameters are call by value.
In the game tree search in Chips we were able to quit looking through moves as soon as we found one that gave us a win. This ends up pruning a large part of the game tree. However, we do not have the equivalent for the kalah game tree search above. This is because we don't have simple wins and losses. We have estimated value from static evaluation functions. Even when we do find a win when the game is over we don't know if a different move might not give us a bigger win, so we keep looking.
It would be useful if there were a way of pruning the game tree for kalah and similar games. In fact, there is. It goes by the somewhat cryptic name of alpha-beta pruning. It is based on the fact that as game tree search progresses the tree we can bound the range of the eventual result. As soon as one move has been completely explored there is a lower bound (called alpha) on what the maximizing player can get. As more moves get explored this lower bound can increase, but will never decrease. Similarly, at levels where the player is minimizing there is an upper bound (called beta) of what the minimizing player is forced to accept. These bounds can be used for pruning.
I will give an example of how pruning is possible using the game tree above. The value of the leftmost child node of the root is 8. Therefore the root, which is maximizing, will end up with value at least 8. In evaluating the center child, we discover that its leftmost node has value of 2. That means that the center node will have value of at most 2, because we minimize at that level. Its value may be smaller. But this means that the root can pick between 8 and something at most 2. The root will never pick the center node. We might as well skip evaluating the other two subtrees of the center node. They cannot change the outcome. They will either be smaller than 2, in which case the center node is even less desirable, or larger than 2, in which case the center node will not select them.
The same reasoning occurs when the maximizing player is looking at moves further down in the tree. The minimizing player has an upper bound beta that can be achieved by some choice other than the one that I am exploring. If I find a move that is worth more than beta I am happy, but my opponent will reject the move that lead to this position and will choose some other move. Therefore there is no sense in me continuing to evaluate moves after I have found a value greater than beta.
Note that the choice of a different move can occur not only at the parent of the current node, but also higher up the tree. It may be the great-grandfather node of the minimizing player who has a better alternative, but no matter where the choice is made once the minimizing player has found a move whose value is less than the current lower bound (alpha) there is no reason to look at further moves.
Just as we saw for regular game tree search it is easier to write code where the player is always
viewing the values from his or her point of view and maximizing, and the values are negated when passed
up to the caller. In this case we have an upper and lower bound, and can quit
exploring moves if we do better than the upper bound. (We also can improve the lower bound
each time we find a better move that we have seen before.) When passing this upper and lower
bound to the next level they are negated and reversed, so the upper bound becomes the lower bound
and vise versa. We can see this in the code for pickMove in
ComputerKalahPlayerAB.
high in the for loop.
However, it does get passed on through to become the high at the next level down.
The basic idea of game tree search with alpha-beta pruning was given is an earlier lecture. The goal here it to describe how to do it by hand. This discussion assumes that we will always maximize. We will take the maximum of the negations of the values of the result of evaluating each move from the opponent's point of view to get the value of our move.
The basic idea is to keep a range (low, high) that the value of this node's evaluation must fall in for this node to be on the path of optimal moves. If we find a value bigger than low we update low to take this into account. If we find a value bigger than high that means that we should stop exploring this node. The high value says that the opponent already knows of a choice that will keep my score no bigger than high. If I find a choice which is better, that means that the opponent will simply choose a different move further up the tree, so there is no sense in looking further. My score at this node can only get bigger, and it is already too big for my opponent to let me get to this node.
If the current values are low and high, the values on the next level will be -high and -low. This is because negating the values of the opponent's moves both negates the two values and reverses which is the bigger of the two.
In class I will demonstrate on this example from the W12 final exam.
The solution is:
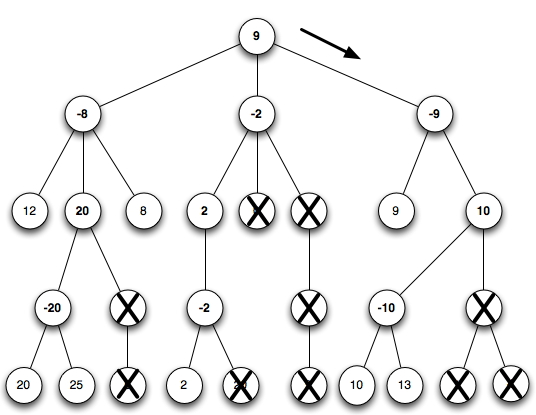
Let's examine this search. We go down the left side of the tree to the leaf labeled 12. Each node is passed a range (-inf, inf). When the 12 is returned to its parent it has its sign reversed to -12. It becomes the new low, giving a range (-12, inf). The range passed to the internal node labeled 20 is therefore (-inf, 12). The range passed to the node labeled -20 is (-12, inf). When we look at the child labeled 20 it returns a value -20. This is smaller than -12, so no update is done. The next leaf node returns -25, which is still smaller. Therefore the node gets the value -20, which is passed up as 20 to the node labeled 20.
The range on the internal node labeled 20 was (-inf, 12). We replace -inf by 20, getting a range (20,12). But the low is bigger than the high. This means that we stop exploring choices and prune the other branch from the node labeled 20. The reason is that the node labeled -8 has found a choice that will allow it to get at least -12. If it were to choose its second child (the node labeled 20) it would end up with a value at most -20. Therefore it will never choose its second child, and we can stop searching. The node labeled -8 continues searching and finds the third child return a -8, which is an improvement on the -12 and makes its range (-8, inf). It also is the node that the node labeled -8 chooses.
Continue the process for the other nodes.
It pays to narrow down the range as soon as possible. Therefore it pays to evaluate the good moves early in the search. It can be useful to use a static evaluation function, or even a shallow lookahead, to sort the moves in decreasing order of apparent value. Some game-playing programs do this to speed up their run time and allow them to look deeper into the game tree.
There is another way to speed up search. Instead of starting the search with low as negative infinity and high as infinity you can pick a narrow range of values around the answer that you expect. (Maybe you remember the value of the last move that you made and you assume that the value of moves doesn't change that fast, so you choose low a bit below that value and high a bit above it.) If the answer you get back is strictly between the low and high values that you chose then it is the correct answer. If not, the answer may not be correct and you have to start the search over again with a wider range (perhaps falling back to negative infinity to infinity).
There is a design pattern called the Model/View/Controller pattern. It suggests separating the program into three interacting parts. The first is the model - the representation of the state of the system that you are dealing with. It has all of the instance variables needed to model the state of the system and all of the methods needed to update that state and return information about that state. The second is the view - how the program presents information and interacts with the outside world. The third is the controller - the part of the program that manipulates the model and interacts with the world via the view.
For Kalah the model consists of the KalahGame class, along with the KalahPlayer class and its concrete implementations HumanKalahPlayer, ComputerKalahPlayerGTS, and ComputerKalahPlayerAB. We have two computer players because they use different forms of game tree search. We saw the two algorithms for game tree search above.
The controller is the part of the program that controls the process and tells the model to
update itself as things change. In Kalah the Kalah class
does this, as the Chips class did in the Chips program. In fact, the two classes
have almost exactly the same structure.
The view is something new. It controls how the model is presented to the world and how the
controller interacts with the world. The Kalah program has an interface
KalahView and two concrete implementations:
KalahViewText and
KalahViewGraphical. KalahViewGraphical
uses KalahFrame to actually display the board.
By isolating the view part of the program we are able to switch from a text-based interface to a
GUI interface by picking which constructor to call in the Kalah class.
Note the flexibility that this offers. Changing the rules of the game (or even the game itself!)
can be done by modifying the model. The controller would work for almost any turn-based game, given
a model that implemented the methods that it calls. We have supplied two different views and could
supply others. The rest of the program does not have to worry about how the information is presented
to and received from the world. (This is not quite true for the Kalah program. The model has to
have two different move methods, one for views that will present the state after the move
and the other for views that want to interactively display changes as we go along. But we could still
have a text view that presented each change as it occurred or a graphical view that just showed the
final position, so in that sense the model and the view are independent, even though they interact.)